Écrire des documents d’architecture technique peut être un peu casse-pied mais c’est très important pour un projet. C’est au cœur du travail d’un architecte technique parce qu’il détaille tous les choix que vous avez conduits et qu’il précise ce qui est attendu de la part des équipes de développement. Ils sont aussi indispensables pour communiquer efficacement avec les différentes parties prenantes (service IT du client, hébergeur, etc.) et pour garantir une mise en œuvre cohérente. Alors, prenons notre courage à deux mains, voici quelques idées générales pour bien rédiger de tels documents :
- Évidemment, on va faire une introduction pour présenter le projet et son contexte et quel est l’objectif et la portée du document.
- On va ensuite présenter la portée fonctionnelle du projet et les contraintes et les normes auxquelles l’architecture doit se conformer.
- Notez que la rédaction de ces documents implique également l’hébergeur / infogéreur de la solution. Pensez-donc à les rédiger conjointement, ou à minima à lui soumettre pour relecture et validation.

Petit tour de ces documents d’architecture technique indispensables :
Document 1 – DAT (Documents d’Architecture Technique) – Architecture d’exécution
Une fois cette introduction faite, on y est, on peut alors commencer à rentrer dans le coeur du document qui est l’architecture d’exécution :
- 1. Architecture d’exécution globale : vue d’ensemble de l’architecture globale du projet, faire des schémas et des diagrammes pour illustrer les composants clés et leurs interactions est indispensable.
- 2. Architecture d’exécution détaillée : faire une description détaillée de chaque composant du système, y compris les serveurs, les bases de données, les logiciels, les modules, etc.
- 3. Flux de données interne à l’application : Diagrammes (souvent aussi appelé “Matrice”) de flux de données montrant comment les données circulent entre les composants. Détail sur la manière dont les données sont collectées, stockées, traitées et transmises.
Il est intéressant d’y annexer un ADR (Architecture Decision Records) qui va lister les décisions / changements d’architecture qui ont été faits au cours du temps, c’est assez pratique pour les nouveaux arrivants pour comprendre l’histoire du projet. - 4. Intégrations et interfaces : Description des interfaces avec d’autres systèmes, services ou applications externes. Protocoles de communication, formats de données, etc.
Document 2 – Sécurité
Et, puis on détaille d’autres éléments qui concernent l’architecture de la sécurité :
Décrivez quelle est l’implémentation de la sécurité ?
- L’identification d’un utilisateur est-elle basée sur un cookie de session, un jeton JWT, etc… ?
- Y a-t-il des protocoles particuliers implémentés (SAML, OAuth 2.0, OpenId Connect, etc.) ?
- Si votre application a la responsabilité de gérer l’authentification (ex: login / mot de passe), décrivez les règles et le mécanismes mise en œuvre (complexité et renouvellement des mots de passe, prise en compte des échecs d’identification répétés, logs, …).
Mentionnez également la stratégie de gestion des permissions : comment sont-elles associées à un utilisateur (techniquement et fonctionnellement), et quelles sont les briques techniques utilisées (annotations / attributs, Voters, middlewares) ?
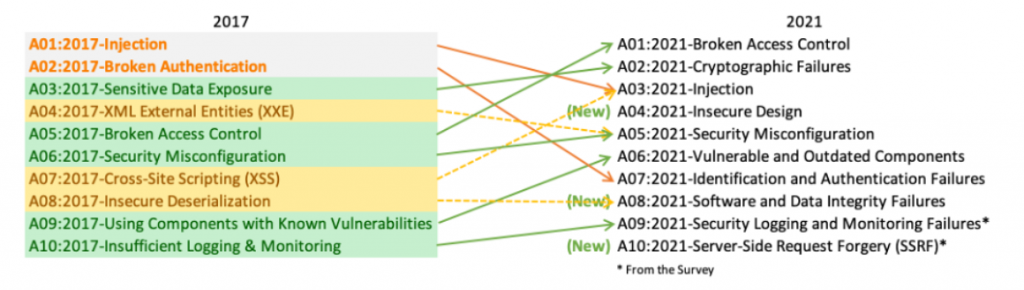
Détail qui a son importance : on oublie souvent de décrire la gestion des accès horizontaux et c’est souvent un cause de faille de sécurité #OWASP_A01.
L’application traite-t-elle de la donnée sensible ?
Si oui, décrire les mesures de durcissement mises en place pour en assurer la protection.. Enfin, comment suivre l’application dans le temps : lister les dépendances et les versions des langages / librairies que vous utilisez, et décrire comment les maintenir à jour.
Document 3 – Architecture de développement et de production
Enfin, on décrit les éléments qui concernent l’architecture de développement et de production voire l’architecture physique :
- 1. Développement et déploiement : Processus de déploiement, gestion des mises à jour et des correctifs (Intégration continue, description du choix effectué pour le workflow GIT, règles de soumission et de relecture des pull-requests, etc.).
- 2. Plan de test : Stratégie de test, y compris les scénarios de test, les plans de test d’acceptation, les tests de performance, etc.
- 3. Gestion des versions et des modifications : Processus de gestion des versions du logiciel et des modifications apportées à l’architecture.
- 4. Gestion des erreurs et de la reprise après sinistre : Plans pour la gestion des erreurs, la surveillance, la journalisation des incidents. Stratégies de reprise après sinistre en cas de panne système.
- 5. Architecture physique : description des serveurs selon les différents environnements.
Quelques bonnes pratiques en plus
Outils de modélisation
Les outils de modélisation et de visualisation (UML en particulier) peuvent apporter une aide efficace dans la représentation des architectures complexes. Ils permettent de conceptualiser, communiquer et documenter l’architecture de manière claire et compréhensible. L’inconvénient est que ces outils donnent une vision souvent très détaillée de l’architecture technique que l’effort pour maintenir ces représentations est assez important… Il est possible de s’en passer sur des projets de taille moyenne mais si vous êtes sur un projet énorme, je vous le conseille vivement !
Les mises à jour
Mettre à jour ces documents d’architecture technique régulièrement est très important, le suivi (et les explications) des changements que l’on apporte à l’architecture permet d’éviter de tourner en rond autour des choix techniques… Et, il y aura forcément un sujet de dette technique un jour ou l’autre.
La rédaction
Assurez-vous que ces documents d’architecture technique sont clairement rédigés, bien organisés et accompagnés de schémas et de graphiques pour faciliter la compréhension. Une fois ces documents d’architecture technique finalisés, ils doivent être partagés avec l’équipe de développement, les parties prenantes et toute personne impliquée dans le projet pour s’assurer que l’architecture est correctement comprise et acceptée.
Conclusion
Pour conclure, écrire de la documentation n’est pas forcément ma passion (je préfère coder) mais ces documents d’architecture technique sont essentiels pour la réussite d’un projet. Lorsque ces documents manquent sur un projet, cela fait perdre beaucoup de temps et ne me rassure pas vraiment sur la qualité du projet ! Allez, hop hop hop, on me fait de beaux docs !
TheCodingMachine vous accompagne dans vos besoins de conception de projet : de la conception fonctionnelle, conception technique ou encore de rédaction de spécifications.
Contactez-nous pour en savoir plus !