Détectez les anomalies avant vos utilisateurs
Monitoring continu, alertes proactives et gestion d'incidents 24/7 : on surveille vos applications en permanence pour intervenir au premier signal faible, avant que l'incident ne devienne critique.
Qu'est-ce que le support & supervision ?
Le support & supervision consiste à surveiller en continu l’état de santé de vos applications web : disponibilité, performances, erreurs, sécurité, infrastructure, pour détecter les anomalies avant qu’elles n’impactent vos utilisateurs et déclencher les bonnes actions au bon moment.
Contrairement à la maintenance corrective qui intervient après l’incident, la supervision est proactive : elle détecte les signaux faibles, lève des alertes ciblées et nous permet d’agir avant la panne. C’est l’assurance d’une application stable et d’une équipe technique en veille permanente.
Quand avez-vous besoin de supervision ?
Votre application est critique pour votre activité ou vos clients
Vous apprenez les incidents par vos utilisateurs ou clients
Vos performances se dégradent sans que vous sachiez pourquoi
Vous n'avez pas de visibilité sur l'état de vos serveurs ou API
Vous avez besoin d'une astreinte technique en dehors des heures de bureau
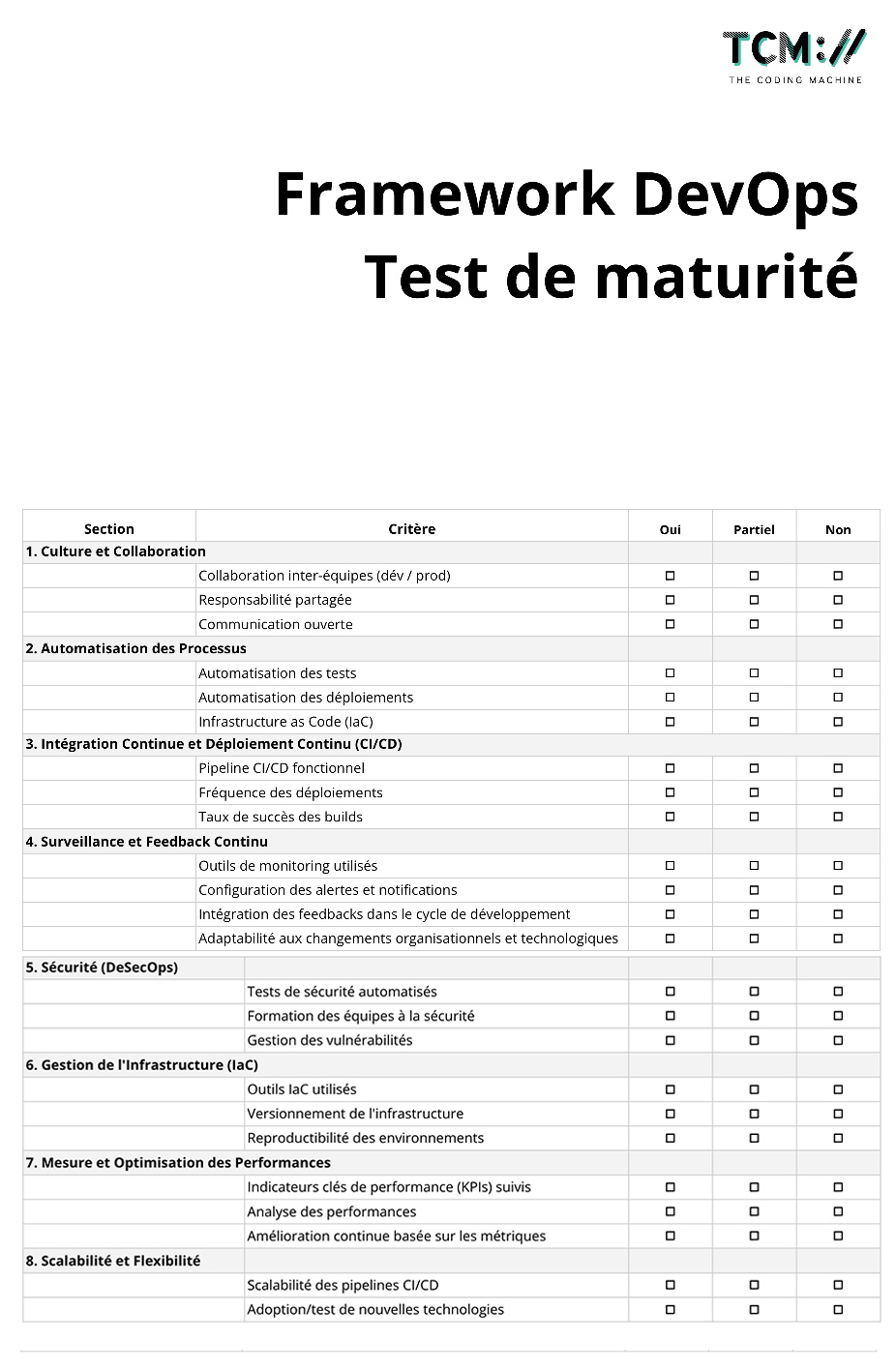
Ce que couvre le support & supervision
Performance applicative
Temps de réponse, latence, requêtes lentes, taux d'erreur HTTP. Détection des dégradations avant impact utilisateur.
Infrastructure & ressources
CPU, RAM, disque, réseau, base de données. Alerte sur saturation, fuite mémoire, espace disque, files d'attente.
Erreurs & exceptions
Capture en temps réel via Sentry / Datadog. Regroupement intelligent, contexte complet, priorisation automatique.
Logs centralisés
Agrégation, indexation et recherche dans tous vos logs applicatifs et serveurs. Corrélation rapide en cas d'incident.
Sécurité & certificats
Expiration SSL/TLS, vulnérabilités CVE, tentatives d'intrusion, anomalies de trafic, conformité RGPD.
Parcours utilisateurs critiques
Surveillance des tunnels clés (connexion, paiement, checkout) via des tests bout-en-bout automatisés.
Astreinte & gestion d'incidents
Astreinte humaine 24/7 sur les incidents P1. Diagnostic, escalade et résolution coordonnée par un ingénieur senior.
Reporting & SLA
Tableaux de bord mensuels : uptime, MTTR, incidents traités, conformité SLA. Transparence totale sur la qualité de service.
De la mise en place à la résolution en 4 étapes
Audit & cartographie
Inventaire de vos applications, services, dépendances et points critiques. Définition des indicateurs (SLI) et des seuils d'alerte adaptés à votre contexte métier.
Audit complet sous 5 joursMise en place du monitoring
Déploiement des sondes, agents, intégrations (Datadog, Sentry, Grafana…), création des dashboards et configuration de l'alerting (PagerDuty / Slack / email) avec règles anti-bruit.
Opérationnel sous 2 à 3 semainesSupervision continue & astreinte
Surveillance 24/7 par nos équipes. À chaque alerte critique, un ingénieur prend le relais : qualification, diagnostic, action ou escalade vers l'équipe de maintenance corrective.
P1 : prise en charge <15 minReporting & amélioration continue
Rapport mensuel : uptime, MTTR, incidents traités, conformité SLA. Recommandations pour réduire la récurrence et améliorer la résilience de votre stack.
Comité de pilotage mensuelPrêt à dormir tranquille ?
Parlons de vos applications et de leurs points critiques.
Comment on a évité une panne avant qu'elle n'arrive
Alerte (3h12 du matin)
Plateforme e-commerce : l'alerte Datadog détecte une fuite mémoire progressive sur le service de catalogue. Aucun utilisateur impacté à ce stade, mais la mémoire est consommée à 78% et grimpe.
Diagnostic (20 min)
L'astreinte prend l'alerte. Analyse des logs et du profiling : une requête mal indexée déclenchée par un script cron consomme la mémoire. Sans action, crash estimé sous 2h en pleine période de soldes.
Résolution & Sécurisation (45 min)
Action immédiate : redémarrage roulant des pods, hotfix d'indexation déployé via CI/CD et 6h de surveillance. À froid : remise d'un post-mortem au client, ajout de nouvelles alertes et de tests de charge automatisés.
Résultat
Questions sur le support & supervision
Faut-il que mon application soit hébergée chez vous ?
Non. On supervise vos applications quel que soit l’hébergeur (AWS, GCP, Azure, OVH, Scaleway, on-premise…). Nos outils s’intègrent en mode agent ou sondes externes, sans dépendre du fournisseur cloud.
Utilisez-vous vos propres outils ou les miens ?
Les deux. Si vous avez déjà Datadog, Sentry, New Relic ou Grafana en place, on s’y branche et on les exploite. Sinon, on déploie une stack adaptée à votre budget et votre criticité (de l’open-source Prometheus/Grafana au SaaS Datadog).
L'astreinte 24/7 est-elle assurée par des humains ?
Oui. Les alertes P1 sont prises en charge par un ingénieur senior d’astreinte, en France, joignable en moins de 15 minutes, soirs et week-ends inclus. Pas de centre offshore, pas de scripts génériques.
Comment évitez-vous l'alert fatigue ?
On configure des seuils intelligents, des regroupements d’alertes et des runbooks par typologie. Chaque alerte qui sonne doit être actionnable. On revoit la pertinence des règles tous les mois lors du comité de pilotage.
Le support & supervision est-il inclus dans un contrat TMA ?
Oui, c’est l’une des briques de tout contrat de maintenance applicative. Elle se combine naturellement avec la maintenance corrective (résolution des incidents détectés), évolutive et préventive.
Les autres types de maintenance
Corrective
Résolution d'incidents, hotfixes en production, post-mortem documenté.
Évolutive
Ajout de features, amélioration UX, optimisation des performances.
Préventive
Mises à jour, patches, réduction de la dette technique.
Support et supervision
Surveillance continue, alertes proactives, gestion des incidents.