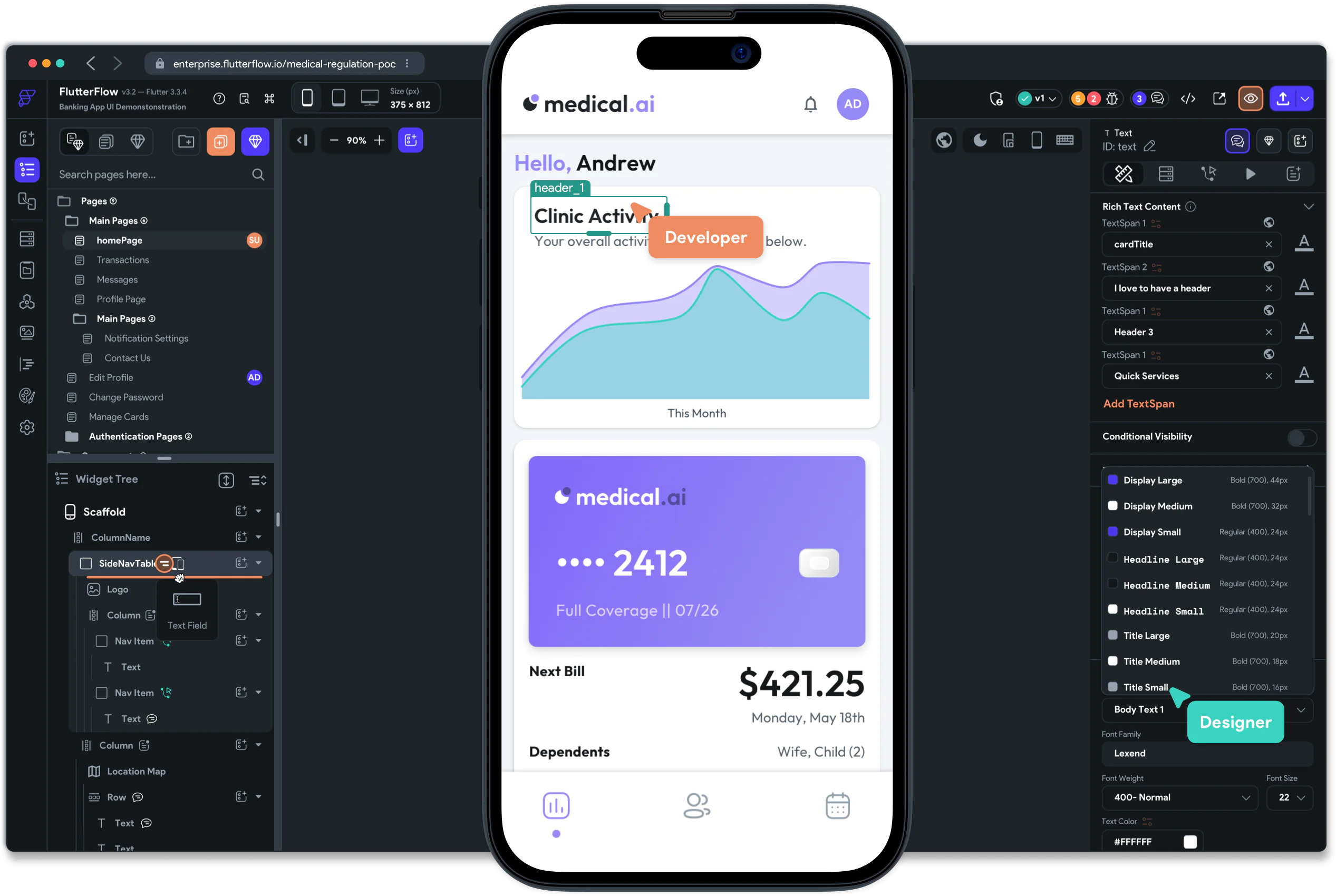
FlutterFlow émerge comme une solution innovante qui promet de transformer la manière dont les développeurs et les concepteurs abordent la création d’applications. Cette plateforme de développement visuel pour Flutter offre une approche simple et rapide, rendant le développement d’applications assez efficace ! Cet article vous propose d’explorer les avantages et les fonctionnalités clés de FlutterFlow, et de découvrir comment il deviendra peut-être un outil incontournable pour les créateurs d’applications mobiles (ou non).
Une interface visuelle intuitive
FlutterFlow présente une interface de conception visuelle drag-and-drop, qui permet aux utilisateurs de construire des interfaces utilisateur (assez élégantes il faut l’avouer) sans écrire une ligne de code ! Cette approche démocratise le développement d’applications en le rendant accessible à quasiement tout le modne, tout en offrant une flexibilité suffisantes pour satisfaire les plus expérimentés. En éliminant les barrières techniques, FlutterFlow ouvre la voie à une créativité sans précédent dans le développement mobile.
Des fonctionnalités riches et extensibles
FlutterFlow n’est pas seulement un outil de conception ; c’est aussi une plateforme complète qui intègre des fonctionnalités avancées telles que l’authentification des utilisateurs, la base de données Firestore, et même l’intégration d’API personnalisées. Les développeurs peuvent ainsi créer des applications assez riches et interactives, allant des simples applications de portfolio aux solutions e-commerce complexes. De plus, FlutterFlow offre la possibilité d’ajouter du code Dart personnalisé, offrant ainsi des outils performants pour étendre les fonctionnalités au-delà de ce qui est possible via l’interface.
Collaboration et productivité
FlutterFlow favorise aussi la collaboration en équipe grâce à ses fonctionnalités de partage et de versionning intégrées. Les équipes peuvent travailler ensemble en temps réel, partageant des projets et des composants d’UI, ce qui accélère le processus de développement et améliore la cohérence de l’application. Cette approche collaborative permet en particulier de prototyper très vite une application.
FlutterFlow : un pont vers le code natif
Ce qui nous plaît peut-être le plus est que FlutterFlow génère du code Flutter natif. Cela signifie que les applications créées avec FlutterFlow peuvent être exportées et améliorées dans un environnement de développement Flutter classique. C’est une vraie nouveauté ! Cette flexibilité en fait un outil extrêmement puissant dans l’arsenal de tout développeur d’applications Flutter.
Bon, il a malgré tout quelques inconvénients, on ne va pas vous mentir …
Dépendance à la plateforme
La plateforme introduit une couche de dépendance supplémentaire dans le cycle de développement. Les applications développées sont, dans une certaine mesure, dépendantes des fonctionnalités et des limitations de FlutterFlow. Si la plateforme ne prend pas en charge certaines fonctionnalités Flutter récentes ou si elle est lente à se mettre à jour, cela peut retarder ou compliquer l’implémentation de ces fonctionnalités dans votre application.
Gestion des versions et du code source
Bien que la plateforme propose des options de versionning, les développeurs habitués à des systèmes de gestion de versions comme Github peuvent trouver ces fonctionnalités limitées. La gestion fine des branches, des merges, et des rollbacks pourrait être plus compliquée, surtout dans les grosses équipes de développement ou pour des projets avec un cycle de vie long et complexe.
Conclusion
Alors, on pense que c’est une vraie avancée dans le développement d’applications mobiles, offrant une plateforme puissante qui allie simplicité, flexibilité et collaboration. Que vous soyez un concepteur d’UI aspirant à donner vie à vos créations, un développeur cherchant à accélérer le processus de développement, ou une équipe désireuse de travailler de manière plus intégrée, la plateforme offre les outils nécessaires pour transformer vos idées en applications fonctionnelles et esthétique. Avec FlutterFlow, l’avenir du développement d’applications mobiles semble non seulement plus accessible, mais aussi plus prometteur en termes d’efficacité.
L’Inversion de Dépendance (IoD) est un concept fondamental en développement qui contribue à la flexibilité et à la modularité du code. C’est l’un des cinq principes SOLID, qui guident les développeurs vers une architecture plus compréhensible, flexible et maintenable. Pour résumer ce principe : les modules de haut niveau ne doivent pas dépendre des modules de bas niveau, mais tous deux doivent dépendre d’abstractions. Mais, je comprends parfaitement que cela ne soit pas très clair… Alors détaillons un peu !
Qu’est-ce que l’Inversion des Dépendances ?
L’IoD, souvent confondue avec l’injection de dépendances, alors que c’est en réalité un principe plus large. Elle se résume en deux règles majeures :
Les modules de haut niveau ne doivent pas dépendre des modules de bas niveau. Cela signifie que les fonctionnalités majeures dans une application ne doivent pas être influencées par les détails de leur mise en œuvre.
Les abstractions ne doivent pas dépendre des détails; les détails doivent dépendre des abstractions. Cela met en avant la nécessité de définir des interfaces ou des classes abstraites qui dictent ce qu’une fonction ou un module fait, sans s’encombrer de la manière dont les tâches sont exécutées.
Exemples d’Implémentation en PHP avec Symfony
Exemple 1 : Notification System Dans un système de notification, plutôt que de coder directement contre une classe de notification par e-mail, on définit une interface NotificationInterface avec une méthode send(). Les différentes implémentations de cette interface pourraient inclure EmailNotification, SMSNotification, etc. Ceci permet au code client de rester le même, même si le mécanisme de notification change.
interface NotificationInterface {
public function send(string $to, string $message): void;
}
class EmailNotification implements NotificationInterface {
public function send(string $to, string $message): void {
// Code pour envoyer un email
mail($to, "Notification", $message);
}
}
class SmsNotification implements NotificationInterface {
public function send(string $to, string $message): void {
// Code pour envoyer un SMS
// Supposons une fonction sendSms disponible
sendSms($to, $message);
}
}
class NotificationService {
private $notifier;
public function __construct(NotificationInterface $notifier) {
$this->notifier = $notifier;
}
public function notify(string $to, string $message) {
$this->notifier->send($to, $message);
}
}
Exemple 2 : Système de Gestion des Utilisateurs Lors de l’enregistrement d’un nouvel utilisateur, au lieu de créer une dépendance directe avec une classe de gestion des données utilisateur, utilisez une interface UserRepository. Cela vous permet de changer les méthodes de stockage (base de données, stockage en ligne, etc.) sans modifier le reste de votre code.
interface UserRepositoryInterface {
public function save(User $user);
}
class MySqlUserRepository implements UserRepositoryInterface {
public function save(User $user) {
// Code pour sauvegarder l'utilisateur dans MySQL
}
}
class UserController {
private $userRepository;
public function __construct(UserRepositoryInterface $userRepository) {
$this->userRepository = $userRepository;
}
public function registerUser(string $username, string $password) {
$user = new User($username, $password);
$this->userRepository->save($user);
}
}
Avantages et Inconvénients
Avantages
Flexibilité : Les modifications ou extensions du système peuvent être réalisées sans affecter les autres parties de l’architecture.
Facilité de test : Les composants peuvent être testés indépendamment en utilisant des mock objects.
Réduction du couplage : Le système devient moins dépendant des implémentations spécifiques.
Inconvénients
Complexité accrue : L’utilisation d’abstraction quand il n’y a qu’un seul type d’implémentation pour le projet (les notifications ne sont que des e-mails pour reprendre l’exemple précédent) va introduire une complexité supplémentaire inutile (over-architecture)
Sur-abstraction : Un excès d’abstractions peut rendre moins lisible les interactions entre les différentes parties de l’application.
Considérations Connexes
En plus des avantages et des défis directement liés à l’IoD, il est essentiel de prendre en compte d’autres aspects qui peuvent influencer son application efficace dans les projets de développement logiciel.
Choix entre Abstract et Interface
Le choix entre utiliser une classe abstraite et une interface est crucial dans l’implémentation de l’IoD :
Abstract : Une classe abstraite permet de définir certaines méthodes qui peuvent être directement implémentées, et d’autres qui doivent être définies par les sous-classes. Cela est utile lorsqu’une partie du comportement doit être partagée entre plusieurs implémentations.
Interface : Une interface ne contient que des déclarations de méthodes sans implémentation. Cela force toutes les sous-classes à fournir leur propre implémentation de chaque méthode, favorisant ainsi un couplage encore plus faible et une plus grande flexibilité.
Utilisation des Traits
Les traits en PHP, par exemple, permettent de réutiliser des ensembles de méthodes dans plusieurs classes indépendantes. L’utilisation des traits doit être réfléchie car, bien qu’ils permettent de réduire la duplication de code, ils peuvent également introduire des dépendances cachées et compliquer la compréhension du flux du programme :
Avantages des traits : permettent la réutilisation du code sans forcer une relation parent-enfant, offrant une flexibilité accrue dans la conception des classes.
Inconvénients des traits : peuvent masquer les dépendances et rendre le code difficile à suivre, surtout lorsqu’ils modifient l’état interne d’une classe ou introduisent des conflits de nommage.
Pratiques de Gestion des Dépendances
L’implémentation effective de l’IoD nécessite souvent un système de gestion des dépendances sophistiqué, tel que ceux fournis par des conteneurs IoC (Inversion of Control) dans des frameworks comme Symfony. Ces outils facilitent l’instanciation et la gestion des dépendances, souvent à travers des annotations, permettant une flexibilité et un découplage maximal du code.
Implications sur les Patterns de Conception
L’adoption de l’IoD favorise également l’utilisation de divers patterns de conception :
Factory Pattern : Permet de centraliser la création d’objets, ce qui est particulièrement utile lorsque l’objet doit être créé selon une certaine configuration ou un certain contexte.
Strategy Pattern : Utilisé pour sélectionner l’algorithme de comportement d’un objet lors de l’exécution, ce qui est pratique pour les systèmes qui doivent être extensibles par rapport aux types de tâches qu’ils peuvent accomplir.
Observer Pattern : Facilite la notification des changements à plusieurs classes, ce qui est souvent nécessaire dans des systèmes complexes où les actions dans une partie du système peuvent nécessiter des réactions dans d’autres parties.
Chain of responsibility Pattern : Permet de réduire la complexité d’un processus en traitant unitairement chaque règle métier dans une classe dédiée qui interviendra ou non dans le processus selon sa propre décision.
Conclusion
Pour les développeurs, adopter l’Inversion de Dépendance, c’est utiliser un style de conception qui privilégie la flexibilité et la maintenabilité à long terme au détriment d’une légère complexité initiale accrue. Cela encourage à penser au « comment » seulement après avoir défini le « quoi », permettant ainsi de construire des applications plus robustes et évolutives.
Selon nous, la maîtrise de ce principe est essentielle pour créer des logiciels solides et facilement extensibles.
Le monde du développement web n’est pas sans danger ! On ne peut pas nécessaiment éviter les pirates mais on peut chercher à s’en défendre. Naviguer avec TheCodingMachine dans ce monde, on prend le sujet très au sérieux et on vous explique comment.
Cet article détaille toute notre démarche, les différentes étapes et précise ce que nous faisons. Embarquez avec nous dans cette aventure où chaque ligne de code est un pas de plus vers le trésor de la sécurité informatique !
L’ISO 27001, notre boussole
Tout bon navigateur a besoin d’une boussole, et c’est là qu’intervient notre norme ISO 27001. Elle est là pour nous guider sur le bon cap, loin des eaux infestées de pirates informatiques. Le document intitulé « Politique de développement informatique sécurisé » fournit un aperçu détaillé des mesures et procédures mises en place par TheCodingMachine pour garantir la sécurité dans le développement de projets informatiques. La gestion et le suivi de cette politique sont assurés via l’outil de gestion de projet Zoho Projects. Des tâches de sécurité spécifiques, comme les audits de code et le suivi des vulnérabilités, sont intégrées automatiquement dans les modèles de projet.
Préparation de la navigation
Dès le début du projet, un responsable de la sécurité est désigné, souvent le chef de projet, accompagné d’un membre de la direction technique. Les premières analyses des points d’attention de sécurité sont effectuées, incluant le contrôle d’accès, la gestion des sessions, le chiffrement, la journalisation, la supervision, et la sensibilité des données.
Dès les premières interactions avec le client, on prépare le voyage : authentification, protection des données, chiffrement.
Cela nous permet de définir le cadre de travail technique : architecture, RGPD, contrôles d’accès (quel “protocole”, quels renforcements), niveau de durcissement applicatif ou encore niveau de durcissement infra. On s’assure que chaque membre de l’équipage connaît son rôle sur le navire. Pas question de naviguer à vue !
En Pleine Mer : Le Développement
C’est en haute mer que l’on peut rencontrer des tempêtes : gestion du code source, choix des outils, revues de code… La sécurisation du code source est une priorité, avec une sensibilisation régulière aux dix principales vulnérabilités selon l’OWASP. Le choix des librairies Open-Source prend en compte la sécurité, avec une attention particulière aux mises à jour et à la communauté qui les soutient. Des revues de code systématiques sont effectuées pour garantir la sécurité et la qualité.
On scrute l’horizon pour éviter les récifs cachés des vulnérabilités.
L’atterrissage
Avant la mise en production, on effectue un dernier audit minutieux. On passe au crible les injections SQL, les failles de sécurité…
Il est temps de surveiller les données de production : il ne doit pas y avoir de données de production en préproduction. Si reproduire le problème n’est pas possible, il faut proposer une reproduction ‘en live’ avec lecture des logs en parallèle dans la mesure du possible. En cas de besoin absolu d’importer les données de production en local, une procédure (incluant une validation du client) doit être suivie et il est nécessaire d’envisager l’anonymisation des données (et détruire les données à la fin du processus).
Après la mise en ligne, la surveillance des vulnérabilités permet de maintenir la sécurité de l’application. Par exemple, chez TheCodingMachine, nous utilisons un outil pour vérifier les dépendances (CKC).
Conclusion
Naviguer avec TheCodingMachine, c’est garantir une aventure sécurisée dans les tumultueuses mers du développement web. On vous promet un voyage aussi palpitant qu’une chasse au trésor, avec la certitude de trouver un butin sécurisé et fiable. Alors, prêts à embarquer avec nous ?
Dans un site, un statut “hors ligne” qui passe à “en ligne” sans que vous n’ayez rien fait ? Un commercial qui vous parle dans une messagerie ? Alors, le web temps réel n’est pas loin…
Le web temps réel est un système permettant de répondre à des évènements dans un laps de temps souvent très court (quelques millisecondes). Dans les projets, le temps réel est très souvent utilisé afin de synchroniser les données de plusieurs utilisateurs et ce, de manière quasi instantanée et simultanée. Et, les applications sont multiples : mises à jour en direct des scores dans les jeux en ligne, collaboration en temps réel comme dans un document, notifications, trading … Il s’agit d’informer les utilisateurs des changements dès qu’ils se produisent, sans nécessiter d’action comme par exemple le rafraîchissement de la page.
Le temps réel en web, c’est quoi au juste ?
Quelques exemples
Un bon exemple, pour illustrer le temps réel est celui des systèmes de messageries instantanées sur les réseaux sociaux. Dans l’application Facebook, les messages sont reçus immédiatement après leur envoi, sans nécessité de rafraîchir la page. Cela marque bien la différence avec les anciennes méthodes qu’on pouvait retrouver sur les boîtes e-mails (le bouton ”envoyer/recevoir”) ou sur les forums de discussion.
Un autre exemple parlant est celui d’un système d’enchères. L’enchérisseur doit voir le montant actuel de l’offre se mettre à jour automatiquement. Sans cela, l’expérience utilisateur pourrait être frustrante. Et c’est tout là l’intérêt du web temps réel : améliorer l’expérience utilisateur.
Si vous voulez faire l’expérience du temps réel, n’hésitez pas à vous rendre dans notre métaverse : Workadventu.re !
Poussons l’explication un peu plus loin …
Le temps réel correspond techniquement à la mise en place d’un système automatisé répondant à des événements divers se produisant sur l’application suite à l’action des utilisateurs (mais pas seulement, on peut imaginer des événements déclenchés par des capteurs de données, des machines) et permettant donc de notifier les autres utilisateurs de la réalisation des dits événements. Evidemment, le temps réel n’est pas obligatoire, la majorité des sites peuvent très bien s’en passer. Pourtant, il est devenu peu à peu indispensable car il améliore énormément l’expérience utilisateur.
Panorama des technologies pour faire du web temps réel
Alors quelles sont les technologies qui permettent de faire du temps réel ? Par exemple, NodeJS est très souvent utilisé notamment pour son système asynchrone non bloquant.
Panorama de ces technologies :
WebSocket
Il s’agit de la technologie la plus répandue. Elle permet d’ouvrir une connexion bidirectionnelle entre un client (un navigateur web) et un serveur puis de persister cette connexion afin que le client puisse envoyer des informations au serveur et vice-versa. Vous pouvez comparer cette technologie à une communication par téléphone.
Des librairies comme Socket.io permettent de “facilement” implémenter les websockets. Des technologies comme Soketi permettent aussi d’installer des serveurs websockets sans trop de configuration de votre part.
Si vous ne souhaitez pas ou pouvez pas développer votre propre serveur de websockets, il existe des services tiers payants comme Pusher ou Ably permettant de vous faciliter le travail. De plus, chez TheCodingMachine, nous sommes certifiés Laravel et ces derniers viennent justement de sortir une technologie first-party pour l’implémentation des websockets : Laravel Reverb, rendant la chose encore plus facile à implémenter d’un point vue technique et sécurité.
SSE (Server Sent Events)
Il s’agit d’une technologie de communication à sens unique : le serveur envoie des données au client quand il en a besoin.
Vous pouvez utiliser un serveur avec Mercure comme solution gratuite et open source.
Si vous n’avez pas besoin de recevoir des données de la part des utilisateurs, c’est un choix solide face aux websockets.
Polling
Ce n’est pas une technologie en particulier mais plutôt un pattern. Le client (navigateur) fait régulièrement des requêtes HTTP au serveur (par exemple toutes les 5 secondes) afin de mettre à jour les données. C’est du rafraichissement automatique.
Attention à la charge des serveurs avec le nombre de requêtes par seconde que cela peut générer. Il s’agit plus d’une synchronisation que d’un temps réel.
WebRTC / Peer-to-peer
Une technologie idéale pour le streaming vidéo ou audio. Fonctionne avec une connexion direct en peer-to-peer (entre deux clients). Vous pouvez utiliser les APIs WebRTC natives disponibles dans les navigateurs modernes afin d’implémenter ce système. Vous aurez certainement besoin d’un serveur de signaling. Il s’agit d’un serveur permettant, lorsqu’un nouvel utilisateur se connecte, de donner la liste des autres utilisateurs afin de savoir avec qui établir le lien peer-to-peer.
Technologie efficace et rapide mais qui a des limites si vous souhaitez connecter de trop nombreux utilisateurs entre eux. Des librairies comme simple peer vous aideront à implémenter cette technologie.
Le WebRTC reste tout de même un cas à part dans l’échange de données en temps réel car il est vraiment développé pour l’échange de voix/vidéo et non de données “simples” où on préfèrera utiliser les autres solutions (ou alors passer par le serveur de signaling).
Et encore quelques autres…
Il existe encore bien d’autres moyens de faire du temps réel :
MQTT : Message Queuing Telemetry Transport → utilisé en IoT, protocole de messagerie en pub/sub (publish / subscribe) avec un système de broker intermédiaire aux clients.
SignalR : spécifique à l’écosystème .NET → similaire au websocket, connexion bidirectionnelle
Long polling : une variante du polling où le serveur retient la réponse à envoyer jusqu’à ce qu’il y ait de nouvelles données.
Un serveur push avec HTTP/2 …
Technologie
Description Simplifiée
Bidirectionnel
Efficacité
Simplicité
Utilisation Typique
WebSocket
Le client (navigateur) et le serveur peuvent s’échanger des informations à tout moment et dans les deux sens.
✅
⚡️⚡️⚡️
➕➕ (grâce aux nombreuses ressources disponibles)
Jeux en ligne, messagerie instantanée, échange de données.
WebRTC Peer-to-Peer
Deux clients s’échangent des données entre eux (très bon pour la vidéo ou l’audio).
✅
⚡️⚡️⚡️
➕➕(grâce aux nombreuses ressources disponibles)
Appels vidéo ou audio.
SSE (Server-Sent Events)
Le serveur envoie des informations au client quand il a des nouvelles.
❌
⚡️⚡️
➕➕
Notifications en direct, actualités, mises à jour.
Polling
Le client fait une requête régulièrement au serveur.
❌
⚡️
➕➕➕
Vérification régulière de nouvelles données, applications très légères.
Prêt à ajouter du web temps réel dans votre application ?
Si vous n’utilisez pas de services payants et décidez d’implémenter vos propres serveurs pour la gestion du temps réel, quelques questions de sécurité et de scalabilité se posent.
Sécurité
En implémentant un système de temps réel, il faut s’assurer que seules les bonnes personnes envoient et reçoivent les données via cette couche supplémentaire.
Cela demande plus de travail pour mettre en place l’authentification, l’autorisation et la gestion des sessions. Assurez-vous aussi de chiffrer vos données en transit en utilisant des protocoles sécurisés comme WSS (websockets) ou HTTPS (polling, sse).
Les données stockées (comme l’historique de chat) devraient aussi être chiffrées / protégées.
Scalabilité
Les applications en temps réel ne sont pas les plus simples à scaler. Si votre application grandit (et votre nombre d’utilisateurs aussi) il faudra opter pour du scaling horizontal avec un système de load balancing.
Déployer votre application avec Docker ou Kubernetes pourra aider. On peut facilement imaginer la duplication des containers faisant tourner le système de temps réel.
Pas de connexion internet ?
Une application en temps réel augmente fortement l’expérience utilisateur mais cela nécessite une connexion internet permanente et stable afin de s’assurer que l’expérience n’en soit pas gâchée.
Conclusion
Le web temps réel, c’est un peu comme de la magie : puissant et utile mais nécessitant de la maîtrise. Que ce soit pour discuter avec des amis, jouer en ligne ou faire des transactions rapides, le temps réel est partout, rendant l’expérience utilisateur plus rapide, réactive et efficace que jamais.
Cependant, son implémentation est loin d’être triviale et nécessite de bien réfléchir à vos cas d’utilisation et à la technologie qui sera la mieux adaptée.
Dans beaucoup de cas, choisir les WebSockets avec un serveur NodeJS et Socket.io fera l’affaire et vous permettra aussi d’expérimenter rapidement.
Si vous ne savez pas ce qu’est la norme ISO 27001, voici un article qui décrit succinctement ce qu’elle est, pourquoi nous faisons cette démarche et où nous en sommes. C’est un projet en cours, pas encore un retour d’expérience. Si vous souhaitez échanger avec moi sur le sujet, n’hésitez pas à prendre contact !
D’abord, quels sont les points clés de la norme ISO 27001 ?
La norme ISO 27001 est une norme internationale de gestion de la sécurité de l’information. Elle est là pour mettre en place, maintenir, surveiller et améliorer un système de gestion de la sécurité de l’information (SMSI) au sein d’une organisation. L’objectif principal de l’ISO 27001 est de garantir la confidentialité, l’intégrité et la disponibilité des informations sensibles et critiques. En quelques points clés :
Elle vise à aider les organisations à établir un cadre pour identifier, évaluer et gérer les risques liés à la sécurité de l’information : la perte de données, la cybercriminalité, les violations de sécurité, les interruptions de service et d’autres menaces liées à l’information.
La mise en place d’un SMSI implique l’identification des actifs d’information critiques, l’évaluation des risques, la mise en place de contrôles de sécurité appropriés, la formation des employés et la surveillance continue de la performance du SMSI.
Les organisations doivent être auditées par des tiers indépendants pour vérifier leur conformité à la norme ISO 27001.
Cette norme encourage enfin l’amélioration continue de la gestion de la sécurité de l’information. Les organisations sont incitées à surveiller et à réviser régulièrement leur SMSI pour s’assurer qu’il reste efficace face aux menaces changeantes.
Pourquoi mettre en place cette démarche ?
Nous avons entamé cette démarche, il faut l’avouer, un peu sous la contrainte. Un de nos gros clients l’exigeait de la part de ses partenaires. En y regardant de plus près, nous nous sommes dits que cela pouvait être intéressant pour plusieurs raisons :
Mieux protéger les informations sensibles comme les données des clients, les données financières ou bien les secrets commerciaux.
Réduire les menaces et les incidents de sécurité tels que les violations de données, les interruptions de service et les cyberattaques.
Se conformer aux exigences légales et réglementaires en matière de sécurité de l’information.
Renforcer la confiance avec nos clients, nos partenaires commerciaux.
Mieux gérer la continuité des activités, être préparé à faire face aux interruptions de service, aux catastrophes et aux situations d’urgence.
Et puis nous espérons aussi que cette démarche va nous permettre :
D’améliorer notre efficacité opérationnelle en rationalisant les processus et les opérations liés à la sécurité de l’information.
Et éventuellement de réaliser des économies (les incidents de sécurité peuvent entraîner des coûts significatifs).
Ce que nous avons fait et ce qu’il nous reste à faire !
La première chose que nous avons faite est de créer une équipe projet avec des collaborateurs de différents services connaissant nos différents processus : SI, RH, Direction, Commercial, Projets, Direction Technique. Cette équipe accompagnée d’un auditeur externe de France Certification nous a permis de conduire une première évaluation de la situation : l’identification des actifs d’information (les données, les systèmes, les équipements, les documents et les processus), les menaces que nous pourrions rencontrer, les vulnérabilités et les risques associés.
Ensuite, nous avons défini les objectifs de notre SMSI en identifiant les processus, les services, les emplacements et les actifs d’information qui seront inclus dans son périmètre. Nous avons aussi rédigé : notre charte informatique, notre politique de développement sécurisé, notre politique de transfert etc. Nous avons aussi énoncé les engagements de l’organisation en matière de sécurité.
Enfin, nous avons mis en place, les premiers éléments de notre SMSI :
La gestion des actifs d’information comme les données, les systèmes, les équipements et les documents. Par exemple, nous nous sommes rendus compte à cette étape que nos leasings n’étaient pas très bien gérés (nous avions encore des leasings sur des ordinateurs que nous n’avions plus !).
L’analyse des risques de sécurité de l’information en identifiant et en évaluant les risques associés aux actifs d’information. C’est certainement la phase la plus longue, il faut passer sur tous les risques et toutes les vulnérabilités liés à votre organisation.
En fonction des risques que nous avions identifiés, nous avons élaboré et mis en place un plan de traitement et des contrôles de sécurité grâce à l’Annexe A de la norme ISO 27001. Ils incluent des contrôles techniques, organisationnels et physiques.
Le plan de traitement des risques qui définit comment les risques sont évalués, gérés et surveillés au fil du temps.
La structure organisationnelle, y compris les responsabilités et les rôles liés à la sécurité de l’information, a été clairement définie.
Les procédures pour gérer les incidents de sécurité, tout doit être enregistré, étayé et stocké.
Par ailleurs, plusieurs réunions ont été conduites avec l’ensemble des collaborateurs pour les sensibiliser à la sécurité de l’information, pour comprendre les risques et les pratiques de sécurité. Pour rendre le sujet un peu ludique, nous avons même réalisé plusieurs quiz et tests aléatoires afin de nous assurer que le message était bien passé et suffisamment intégré.
Les prochaines étapes sont d’effectuer un audit interne pour évaluer la conformité aux exigences de la norme ISO 27001 et pour identifier les éventuels écarts et l’audit de certification qui sera mené par un organisme de certification accrédité.
Conclusion
La mise en place d’une démarche de certification de la norme ISO 27001 demande du temps et de l’engagement, mais nous estimons qu’elle est essentielle pour renforcer la sécurité de l’information et répondre aux exigences de sécurité.
La suite au prochain épisode : date de l’audit externe septembre ! On vous tient au courant…
Comme toutes nouvelles technologies, l’intelligence artificielle générative fait couler beaucoup d’encre. Dans cet article, nous essayerons de répondre à la question suivante : Comment tirer parti de l’intelligence artificielle générative dans un contexte d’entreprise ?
Petit rappel de ce qu’est l’intelligence artificielle générative… pour ceux qui n’auraient rien suivi !
L’intelligence artificielle générative (IA générative) vise à développer des applications capables de générer du contenu de manière autonome, en imitant ou en simulant des processus de création humaine. Ces systèmes utilisent des modèles d’apprentissage automatique, en particulier des réseaux de neurones, pour produire des données nouvelles et originales sous forme de texte, d’images, de musique, de vidéos, ou d’autres types de médias.
Quelles applications imaginer pour l’entreprise ?
Sur le marché, nous pouvons distinguer deux types d’entreprises : celles dont le cœur de métier est de proposer de l’IA générative (ChatGPT par exemple) et surtout celles qui s’en servent pour améliorer leur offre et leur positionnement concurrentiel sans altérer leur business model.
C’est surtout le deuxième type d’entreprises qui nous intéresse. Et, voici quelques idées d’utilisation de l’IA générative dans ce cadre :
Génération de documents : si vous produisez des documents pour vos clients comme des rapports et des analyses, l’IA peut vous apporter de vrais gains de productivité.
Gestion du service client : les chatbots basés sur l’IA générative peuvent offrir une assistance 24 heures sur 24, 7 jours sur 7, en répondant aux questions des clients, en fournissant des informations sur les produits et en aidant à résoudre des problèmes courants.
Personnalisation de l’expérience utilisateur : les IA génératives peuvent analyser les données des clients et créer des recommandations personnalisées pour les produits par exemple.
Autrement, l’IA peut être massivement utilisé en interne pour beaucoup d’usages :
pour l’optimisation des opérations : planification de la chaîne d’approvisionnement, gestion des stocks, planification des horaires et prévision de la demande.
la génération de développement, en générant automatiquement des parties de code source.
la création de contenus de formation
ou les analyses prédictives et prévisions : les IA génératives peuvent analyser les données historiques et créer des prévisions pour aider les entreprises à prendre des décisions éclairées en matière de planification et de stratégie.
Qu’est-ce que nous faisons aujourd’hui ?
Evidemment, nous développons des projets qui mettent en œuvre de l’intelligence artificielle. Par exemple, nous avons récemment réalisé une application métier où l’utilisateur charge des documents pour qu’ils soient automatiquement vérifiés et analysés dans le but d’extraire des informations pour éviter de les ressaisir. Dans un relevé de compte, par exemple, l’application vérifie que le titulaire du compte correspond à l’utilisateur puis remonte le numéro de compte automatiquement.
Un autre exemple d’un projet réalisé pour un client à Hong-Kong, le développement d’une application permettant de générer un audit technique pour des bâtiments de manière automatique à partir des données et des commentaires saisis par l’utilisateur.
Mais c’est en interne que l’intelligence artificielle est encore plus intéressante. Nous en tirons déjà beaucoup d’avantage :
Créer des idées de contenus et écrire ces contenus beaucoup plus rapidement (seriez-vous capable de deviner quelles phrases de cet article ont été générées par l’IA ?). Evidemment, le contenu généré ne sera pas parfait et donc doit être relu et ajusté mais il constitue un socle de départ qui est en général de bonne qualité.
Assister nos collaborateurs pendant la phase de conception des applications métiers de nos clients en générant par exemple les compte-rendus des ateliers, en analysant les modèles de données produits etc.
Pour développer, les jeunes embauchés n’utilisent plus Stackoverflow pour chercher des solutions à leurs problèmes techniques. Ils préfèrent à cela ChatGPT ! Ça n’a l’air de rien mais c’est un changement fondamental dans la recherche de l’information.
Et, on espère que les tests unitaires voire les tests fonctionnels pourront bientôt être générés (parce que cela nous changera la vie).
Conclusion
On est encore loin de pouvoir générer une application même si d’énormes progrès ont été accomplis. Le NoCode, sur lequel nous écrivions un article l’année dernière couplé à de l’intelligence artificielle générative pourrait faire le web de demain… à suivre donc !
Les solutions de paiement sur un site web marchand ne sont pas seulement variées ; elles sont très importantes pour l’expérience utilisateur, la conversion des ventes ou bien encore pour la sécurité des transactions. Choisir la bonne solution peut non seulement améliorer l’expérience d’achat mais peut aussi étendre votre portée à l’international. Voici un panorama approfondi des principales options disponibles. On fait souvent tous ces types d’implémentation chez TheCodingMachine ; on finit par bien les connaître. Elles permettent de répondre aux différents besoins des e-Commerçants : paiements par carte, paiements récurrents, gestion des abonnements et parfois plus encore !
Passerelles de paiement
Ces solutions de paiement, idéales pour les startups, entreprises en ligne, développeurs, et e-commerçants de toutes tailles, offrent une intégration facile et une gestion flexible des paiements en ligne.
Par exemple, PayPal, connue pour sa facilité d’utilisation et sa reconnaissance internationale, bien qu’elle puisse présenter des frais plus élevés pour les transactions internationales. Stripe se distingue par sa facilité d’intégration et sa flexibilité, supportant une grande variété de méthodes de paiement, y compris les cryptomonnaies dans certains marchés. Square fusionne les mondes en ligne et physique, offrant une solution de paiement intégrée qui comprend un traitement des paiements en ligne et un point de vente mobile. Adyen, quant à elle, cible principalement les entreprises de taille moyenne à grande avec sa capacité à accepter une vaste gamme de méthodes de paiement internationales et sa structure de frais personnalisable.
Solutions de paiement par les banques
Les banques traditionnelles, telles que la Société Générale avec son offre Sogenactif, ciblent leurs clients allant des PME aux grandes entreprises, cherchant à intégrer une solution de paiement en ligne sécurisée avec le support d’une banque reconnue. Les terminaux de paiement virtuels offerts par les banques permettent de traiter les paiements par carte de crédit via un terminal virtuel. C’est une option sûre mais qui a souvent des frais élevés. Les virements bancaires, quant à eux, offrent une méthode sécurisée pour les transactions importantes, bien qu’ils puissent être moins pratiques pour certains clients.
Paiement par virement Open Banking
Une autre solution de paiement disponible : les paiements par virement via l’Open Banking. Par exemple, l’API Bridge (en plus, c’est un de nos clients, donc on en profite pour lui faire un peu de pub !). Ces solutions offrent une alternative moderne et efficace aux méthodes traditionnelles de paiement. Contrairement aux banques qui imposent souvent des frais élevés pour les transactions, l’Open Banking offre une solution plus économique et transparente.
Avec l’API Bridge, les entreprises peuvent tirer parti de la connectivité entre les institutions financières en toute sécurité afin de faciliter les virements bancaires en ligne. Cette approche permet d’éliminer les intermédiaires coûteux et de réduire les frais associés aux transactions. De plus, les paiements par virement via l’Open Banking offrent un niveau élevé de sécurité, grâce à l’authentification forte et aux protocoles de chiffrements avancés.
Cryptomonnaies
Si vous voulez explorer des territoires plus innovants voire un peu exotiques, les solutions de paiement en cryptomonnaies telles que BitPay et Coinbase Commerce offrent aux e-commerçants une opportunité de capter une clientèle à la recherche de méthodes de paiement beaucoup plus modernes. BitPay permet, par exemple, les paiements en Bitcoin et autres cryptomonnaies, une option qui se développe en offrant des frais réduits et des transactions sécurisées. Coinbase Commercefacilite l’acceptation des cryptomonnaies, simplifiant l’intégration pour les entreprises de toutes tailles.
Paiements mobiles
L’évolution du commerce mobile redéfinit les paiements en ligne, avec des solutions de paiement comme Apple Pay, Google Pay, et Samsung Pay qui facilitent les achats en magasin ou en ligne via smartphone. Ces méthodes offrent une expérience d’achat rapide et sécurisée, tirant parti de la technologie NFC pour des transactions sans contact. L’intégration de ces options de paiement mobile peut significativement améliorer l’expérience utilisateur, en particulier pour les acheteurs utilisant leurs appareils mobiles pour naviguer et acheter.
Solutions locales et spécifiques à certains marchés
Pour les marchands visant une clientèle internationale, il est crucial d’offrir des méthodes de paiement adaptées à chaque marché. Alipay domine en Chine avec sa plateforme de paiement mobile et en ligne, tandis que PayU, Mollie, et Klarna fournissent des passerelles de paiement localisées en Europe, supportant des méthodes de paiement préférées comme iDEAL aux Pays-Bas ou Sofort en Allemagne. Intégrer ces solutions peut aider à pénétrer ces marchés en offrant aux clients des options de paiement familières et sécurisées.
Conclusion
Votre solution de paiement pour votre site marchand devra prendre en compte plusieurs facteurs critiques : les frais de transaction, la facilité d’intégration, l’expérience utilisateur, la sécurité, et la portée géographique. Adopter plusieurs solutions de paiement est souvent la clé pour répondre à l’ensemble de vos besoins.
Article d’Alexis Prevot Vous avez des questions ? N’hésitez pas à en discuter avec Alexis sur Linkedin.
Même si les méthodes agiles prennent de plus en plus le pas sur des méthodes plus anciennes comme la méthodologie waterfall, avoir un référentiel documentaire et en particulier des spécifications fonctionnelles est indispensable. Selon nous, savoir rédiger des spécifications présente de nombreux avantages :
cela évite le syndrome “never-ending project” : avoir un périmètre clair (même une backlog) n’est souvent pas suffisant pour se dire : “c’est terminé, je passe en prod”. Il est toujours possible de raffiner son projet, d’ajouter telle ou telle fonctionnalité… et donc, cela permet de rassurer le donneur d’ordre (le client) sur l’atterrissage du projet.
cela permet de partager facilement les connaissances pour accueillir de nouveaux développeurs sur le projet par exemple ;
cela permet d’avoir un référentiel avec les utilisateurs lors de la maintenance, de la transmission ou de la refonte d’un projet (mais je connais des entreprises qui font du projet comme nous et qui refusent de maintenir le projet qu’ils ont développé – je trouve que c’est un peu facile !) ;
Alors, comment rédiger des spécifications fonctionnelles de façon efficace et tout en évitant de vous faire perdre trop de temps ?
Note 1 : Pour simplifier cet article, nous ne parlerons que du fonctionnel (donc pas des autres aspects d’un projet comme les performances, la sécurité etc.).
Note 2 : Nous ne parlerons pas non plus des aspects plus généraux tels que la description générale du projet, la vue d’ensemble, le contexte etc.
Quelques conseils généraux pour rédiger des spécifications
Préférez les schémas aux longues explications ! Un bon schéma est souvent plus facile à comprendre.
Essayez de faire des descriptions claires et précises, en évitant le jargon technique excessif. Évitez d’être trop verbeux.
Découpez vos différentes spécifications en éléments digestes, un document de plus de 50 pages n’est pas une bonne idée, il faut trouver la bonne granularité.
N’oubliez pas que c’est un document vivant, susceptible d’être mis à jour au fur et à mesure de l’évolution du projet.. Pensez aussi à la manière de gérer les modifications, les différentes versions, le statut de ce document ou bien encore les revues et la validation.
Pour vous aider dans la conception, n’hésitez pas à utiliser des outils tels que Asana ou encore Jira.
La méthode que j’aime bien
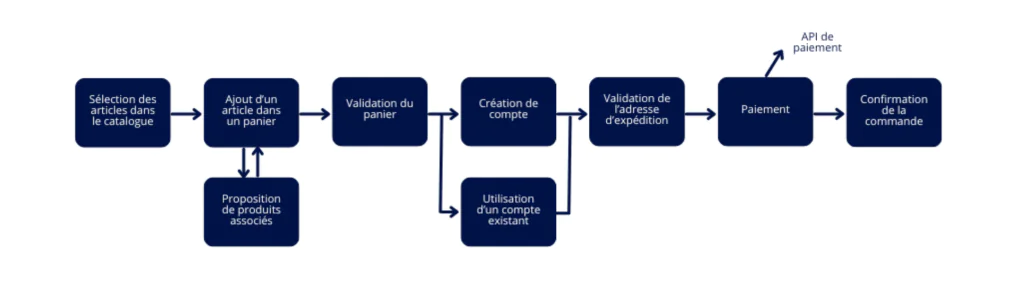
1. La cinématique générale de l’application :
Commencez par le plus général. En général, on peut commencer par un diagramme de processus qui peut représenter les différentes étapes et les affecter à des types d’utilisateurs différents. Dans ce schéma, identifiez les points d’interaction entre les composants et les systèmes.
Par exemple, pour un site e-commerce (pour prendre un exemple que tout le monde connaît), les étapes pourraient être :
Le client sélectionne des produits qu’il ajoute à son panier, il valide son panier, indique s’il dispose d’un compte ou bien en crée un nouveau, valide l’adresse d’expédition, effectue le paiement…
2. Rédigez des scénarios ou des cas d’utilisation :
Pour rédiger des spécifications, commencez par rédiger des scénarios simples. Vous pouvez détailler les éléments suivants :
les différentes interactions : acteurs, les actions possibles et les résultats attendus,
les maquettes des écrans,
les données d’entrée et de sortie,
les règles métiers
la gestion des erreurs, les exceptions
Prenons un exemple, c’est plus parlant :
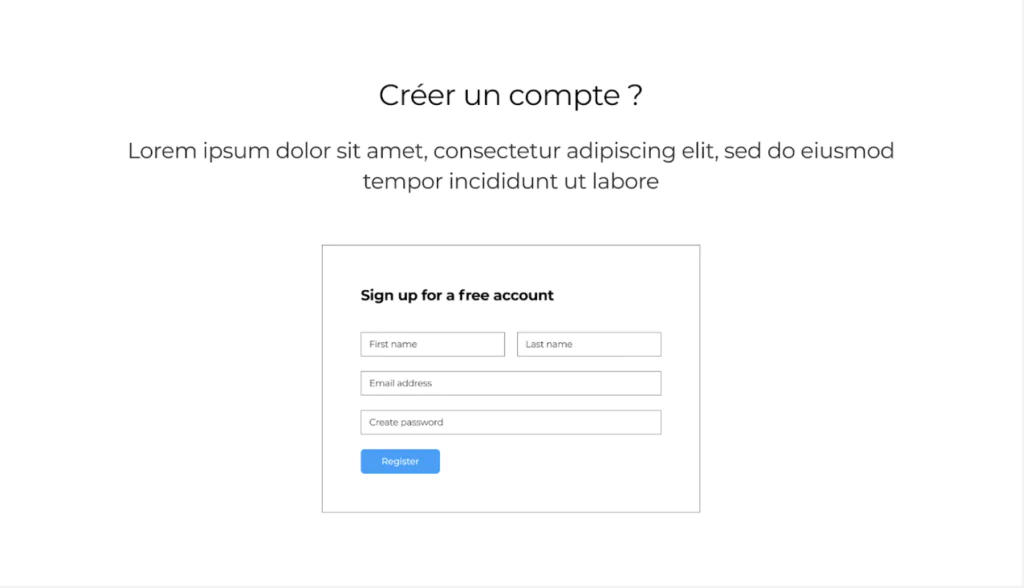
cas d’utilisation n°XXX : Créer un compte client
Acteurs : client
Description : Ce cas d’utilisation permet à un client de créer un compte sur le site e-Commerce, ce qui lui permettra d’accéder à des fonctionnalités personnalisées et de se connecter ultérieurement.
Maquette :
Scénario principal :
L’utilisateur accède à la page d’inscription.
L’utilisateur saisit son nom, son prénom, son adresse e-mail et un mot de passe.
Le système vérifie que l’adresse e-mail est unique.
L’utilisateur confirme la création de son compte.
Le système crée le compte utilisateur et envoie un e-mail de confirmation.
Règles métiers, gestion des erreurs :
Si l’adresse e-mail n’est pas unique, le système affiche un message d’erreur et propose un lien vers la page “mot de passe oublié”. Si l’utilisateur ne remplit pas tous les champs obligatoires, le système affiche un message d’erreur.
Postconditions : Le compte utilisateur est créé, et l’utilisateur reçoit un e-mail de confirmation.
Les erreurs qu’il faut éviter pour rédiger des spécifications fonctionnelles
Manque de clarté et de précision : Les spécifications vagues ou ambiguës peuvent entraîner des malentendus entre les développeurs, les testeurs et les clients. Il est essentiel d’être précis et explicite dans la description des fonctionnalités, des processus et des exigences.
Manque de flexibilité : Les spécifications doivent être suffisamment flexibles pour s’adapter aux changements inévitables qui surviennent au cours du développement du projet. Il est important de prévoir un mécanisme de gestion des changements, permettant d’actualiser le document de façon ordonnée et transparente.
Feedback des Utilisateurs : Les spécifications doivent être orientées utilisateur. Rédiger des spécifications sans avoir les retours des utilisateurs finaux peut conduire à un produit qui ne répond pas à leurs besoins. Il est crucial de mener des analyses des besoins, d’effectuer des tests utilisateurs, et de s’assurer que le document est régulièrement mis à jour en fonction de leurs retours.
Pour conclure
Alors nous savons que rédiger des spécifications fonctionnelles complètes et claires demande des efforts, mais cela contribue au succès du projet en minimisant les ambiguïtés et en alignant les attentes de toutes les parties prenantes.
Par ailleurs, avec un peu d’habitude, vous irez de plus en plus vite et vos spécifications s’amélioreront au fil du temps !
Ceci est une courte introduction au vaste domaine qui est la gestion de la sécurité d’un projet web. Suivre les recommandations de l’OWASP (Open Web Application Security Project) est indispensable pour protéger votre application contre les vulnérabilités et les menaces potentielles.
Il y a trois thèmes à aborder pour gérer la sécurité d’un projet web :
1 – D’abord gérez la sécurité d’un projet web dans le code :
La liste est un peu longue mais voilà les bonnes pratiques que vous devez adopter pour vous assurer que votre code est bien géré, et qu’il respecte les bases en termes de sécurité d’un projet web :
l’authentification : L’authentification est le processus par lequel un système vérifie l’identité d’un utilisateur. Elle repose en général sur le nom de l’utilisateur et un mot de passe. L’authentification garantit que seuls les utilisateurs autorisés peuvent accéder aux systèmes et aux données. Assurez-vous que les mots de passe sont stockés de manière sécurisée à l’aide de hachages et de salages pour protéger les informations d’identification. Vous pouvez aussi utiliser une authentification à multiples facteurs (MFA) pour exiger une méthode d’identification supplémentaire, en plus du mot de passe (par exemple, les banques demandent souvent une confirmation par mobile).
la gestion des sessions : Les sessions sont des mécanismes qui permettent à un site web de maintenir l’état d’un utilisateur entre les différentes requêtes HTTP. Le vol de session permet à l’attaquant d’accéder aux données de l’utilisateur. Pour se protéger, vous pouvez utiliser des cookies sécurisés, la régénération de l’ID de session après l’authentification, la validation stricte des cookies de session ou encore l’utilisation de connexions sécurisées (HTTPS).
la protection contre les injections : L’injection SQL est une technique de piratage qui consiste à insérer du code SQL malveillant dans les saisies d’un utilisateur d’une application. Cela peut permettre à un attaquant de manipuler une base de données ou d’extraire des informations. Pour prévenir l’injection SQL, il est essentiel de valider et de filtrer les entrées utilisateur de manière appropriée. L’utilisation d’un ORM (Object-Relational Mapping) permet en général d’éviter simplement les attaques par injection SQL.
Protection contre les failles de sécurité d’un projet web dans les contrôles d’accès : Appliquez des règles strictes de contrôle d’accès pour garantir que seuls les utilisateurs autorisés ont accès aux ressources sensibles. Assurez-vous que les utilisateurs ne peuvent pas accéder à des parties de l’application auxquelles ils ne sont pas autorisés.
Protection contre les failles XSS (Cross-Site Scripting) : Les failles XSS (Cross-Site Scripting) permettent à des attaquants d’injecter du code JavaScript malveillant dans des pages web consultées par d’autres utilisateurs. Pour prévenir les attaques XSS, il est essentiel de valider et de filtrer les entrées utilisateur et d’utiliser des mécanismes de sécurité tels que les en-têtes de sécurité HTTP et les bibliothèques de sécurité d’un projet web. Les mécanismes de validation et d’échappement permettent à l’application de ne pas exécuter du code JavaScript malveillant.
Protection contre les failles CSRF (Cross-Site Request Forgery) : Ces failles permettent d’exécuter depuis un autre site une action non désirée à l’utilisateur. Par exemple, imaginez que vous visitez un site malveillant qui appelle une URL qui permet de changer votre mot de passe depuis une image. Pour s’en prémunir, vous pouvez utiliser des jetons anti-CSRF pour vérifier l’authenticité des requêtes de l’utilisateur et empêcher ces attaques.
Sécurité des fichiers téléchargés : Restreignez les types de fichiers autorisés à être téléchargés. Assurez-vous que les fichiers téléchargés ne peuvent pas être exécutés sur le serveur. Dans le pire des cas, vous pouvez aussi scanner ces fichiers à l’aide d’un antivirus pour détecter des logiciels malveillants et de limiter les autorisations de téléchargement pour minimiser les risques potentiels.
Chiffrement et sécurité des communications : Utilisez HTTPS pour chiffrer les communications entre le navigateur de l’utilisateur et le serveur web. Assurez-vous de stocker les données sensibles de manière sécurisée.
N’hésitez pas à vous référer aux top 10 OWASP (2021) :
Code
Risque
Commentaire
A1:2021
Broken access control
Restrictions appliquées incorrectement sur ce que les utilisateurs authentifiés ont le droit de faire
A2:2021
Cryptographic failures
Données nécessitant des précautions particulières lors de l’échange avec le navigateur
A3:2021
Injection
Failles d’injection, telles que les injections SQL, NoSQL, OS et LDAP
A4:2021
Insecure design
Failles créées par la conception de l’architecture, du projet
A5:2021
Security misconfiguration
Configurations par défaut non sécurisées ou incomplètes, en-têtes HTTP mal configurés…
A6:2021
Vulnerable and Outdated components
Bibliothèques, cadres (frameworks) et modules vulnérables
A7:2021
Identification and Authentication failures
Mise en œuvre incorrecte de l’authentification et de la gestion des sessions
A8:2021
Software and Data integrity failures
Désérialisation conduisant à l’exécution de code à distance
A9:2021
Security logging and monitoring failures
Permet aux attaquants de poursuivre leurs attaques contre le système
A10:2021
Server-side request forgery (SSRF)
Contourne le pare-feu et permet le scan du serveur (par exemple)
2 – Ensuite, outillez la sécurité :
Au jour le jour, des outils permettent de vous assurer la sécurité de votre application :
Les outils d’analyse statique : ces outils vous permettent d’analyser votre code afin de garantir une certaine cohérence, de limiter le risque de bug ainsi que d’identifier les vulnérabilités de votre code source. Voici quelques outils populaires pour l’analyse statique de code PHP :
PHP_CodeSniffer : Cet outil vérifie certaines bonnes pratiques du code PHP telles que la PSR-12. Il peut également être étendu pour inclure des règles personnalisées.
PHPStan: PHPStan est un analyseur statique avancé qui détecte les erreurs de type ainsi que les erreurs logiques dans le code PHP.
Scrutinizer : Scrutinizer est un outil d’analyse de code en ligne qui prend en charge PHP. Il fournit des rapports détaillés sur la qualité du code, les performances et les vulnérabilités.
PHPStorm : PHPStorm, un environnement de développement intégré (IDE) pour PHP, il a l’avantage de proposer des fonctionnalités d’analyse statique du code intégrées qui signalent les problèmes en temps réel pendant que vous écrivez du code.
la gestion des dépendances : vous devez vous assurer que les dépendances de votre application (bibliothèques, frameworks, modules, etc.) sont à jour et ne contiennent pas de vulnérabilités connues.
Composer : Composer est l’outil de gestion de dépendances le plus largement utilisé en PHP. Il permet de définir, d’installer et de gérer les bibliothèques et les packages PHP, en utilisant un fichier de configuration (composer.json) pour spécifier les dépendances requises. Composer récupère automatiquement les packages depuis le référentiel Packagist et gère les dépendances de manière efficace. Il permet aussi, via sa commande `audit`, de signaler des dépendances vulnérables (qu’il faudrait donc mettre à jour ou changer).
La gestion des logs : ces outils permettent le suivi et l’enregistrement des événements de sécurité, les erreurs et les activités de l’application. La gestion des logs est un élément clé permet de détecter les activités suspectes.
Commencez par sélectionner un système de gestion des logs. PHP propose la fonction “error_log” pour les erreurs qui est souvent suffisante, mais vous pouvez également utiliser des bibliothèques de log PHP comme Monolog ou des outils tiers. Ecrivez ensuite dans votre code des instructions de logging aux points critiques, tels que les erreurs, les événements de sécurité, les connexions réussies/échouées, etc. Enfin, mettez en place une analyse régulière des logs et des sondes d’alertes pour détecter par exemple des tentatives d’intrusion et réagissez rapidement en cas de problèmes !
3 – Enfin, gérez la partie humaine de la sécurité :
Il y a toute une partie humaine pour gérer la sécurité d’un projet web.
la sensibilisation et la formation à la sécurité : Sensibilisez l’ensemble de l’équipe de développement voire vos utilisateurs à la sécurité de votre application. Les connaissances, le partage des bonnes pratiques sont essentielles pour détecter et prévenir les vulnérabilités.
la gestion des incidents de sécurité : chercher à réduire un risque ne signifie pas qu’il est nul. Aussi, n’hésitez pas à préparer un plan de réponse aux incidents de sécurité pour réagir rapidement.
la documentation : Documentez les pratiques de sécurité, les procédures et les politiques de l’application pour que toute l’équipe ait accès aux informations nécessaires.
4 – Quelques expériences horribles…
Nous avons eu l’occasion d’expérimenter quelques-uns des problèmes de sécurité (même si ce n’était pas forcément notre code). Heureusement, nous nous en sommes toujours sorti mais l’expérience est rarement agréable, quelques exemples :
les plus classiques : Pages non protégées dans le back office ou bien oubli de l’annotation @Logged dans certains modules du projet…
Fuites de projets utilisant Git (Salut WordPress !) : Fichier .env commité avec des informations de connexion et impossible à supprimer car Git stocke l’historique …
Les « script kiddies », ces scripts qui scannent le web pour rechercher un site qui n’a pas été mis à jour… Et qui trouvent un de nos sites web avec une vulnérabilité connue et qui en profitent pour le défigurer, affichant des messages politiques plus que douteux. Suivez mon conseil : gardez vos dépendances de projet à jour !
Bref, n’importe quel développeur sérieux sait qu’il va être confronté à un problème de sécurité un jour ou l’autre même s’il a été très attentif. Autant s’y préparer !
En suivant ces bonnes pratiques et en intégrant la sécurité d’un projet web dans tout le cycle de vie de votre développement, vous devriez être en mesure de réduire considérablement les risques liés à la sécurité. N’oubliez pas qu’il est beaucoup moins coûteux de mettre en place ces bonnes pratiques au démarrage du projet qu’à la fin où il faudra gérer d’autres urgences et rattraper potentiellement plusieurs mois de travail !
PS : Si vous désirez aller plus loin, l’OWASP propose des guides et des outils spécifiques pour aider à renforcer la sécurité des applications web.
Vous avez sûrement entendu parler du numérique responsable ! Vouloir réduire l’impact environnemental d’un site web, c’est évidemment bien, le faire c’est encore mieux. Alors comment s’y prendre ? Bien que certains outils permettent d’avoir une vue d’ensemble de votre site web, il est souvent nécessaire d’analyser l’ensemble des pages de votre site une par une et l’examen de nombreuses dimensions est possible. En plus, pour augmenter la difficulté, la plupart des indicateurs techniques sont en partie corrélés.
Bref, cela peut prendre beaucoup de temps, alors cet article présente un condensé des points à surveiller et les outils pour les mesurer.
1. Quels sont les points à surveiller – Les bonnes pratiques du Numérique responsable ?
Le poids de la page
Le poids de votre page correspond à la quantité de données de votre page et se mesure donc en octet (Méga-octets la plupart du temps). Plus la page sera de taille réduite, moins il y aura besoin d’énergie pour la transférer. Comme une page web est constituée de :
D’un DOM (Document Object Model) : c’est le guide qui va renseigner le navigateur sur le contenu et la structure de la page, avant même son rendu.
De code statique : HTML et CSS.
Des scripts (Javascript) permettant d’animer et de dynamiser votre site.
Des fichiers : images, vidéos, …
Des plug-ins ainsi que des solutions tierces.
Le poids de votre page est essentiellement influencé par la quantité et le type de fichiers de votre page. Les images non optimisées peuvent considérablement augmenter la taille d’une page. Un vrai point noir dans le cadre du numérique responsable. Il convient d’utiliser des formats d’image modernes (comme WebP) et des techniques de compression. Il est aussi possible de limiter leur nombre ou de conditionner leur affichage.
Si vous avez besoin de vous donner un ordre de grandeur, vous pouvez trouver des statistiques détaillées du poids des pages web (et de ces différents composants sur le site HTTP Archive accessible via ce lien : https://httparchive.org/reports/page-weight
Le nombre de requêtes
Lorsque vous développez un site web, il comporte de nombreuses parties différentes. Vous avez les différents fichiers d’images que vous utilisez sur une page, les feuilles de style CSS qui contrôlent l’apparence du contenu, les fichiers JavaScript qui ajoutent toutes ces fonctionnalités intéressantes, etc.
Donc, lorsqu’une personne parcourt votre site web, son navigateur doit pouvoir télécharger toutes les ressources nécessaires à cette page à partir de votre serveur. Pour ce faire, il adresse des requêtes HTTP au serveur pour chaque ressource individuelle. Bref, pour faire simple, les requêtes sont ce qui permet à votre site de récupérer toutes les informations dont il a besoin auprès de votre serveur (qui stocke vos données et fichiers).
Toutefois, certains éléments spécifiques vont affecter particulièrement les requêtes, il s’agit par exemples :
D’extensions (fréquentes en WordPress notamment),
Les polices personnalisées et les émojis,
Des scripts liés à des applications tierces.
Pour optimiser les requêtes, il y a trois approches possibles :
Supprimer les requêtes inutiles (par exemple, les extensions WordPress non utilisées – évidemment si vous utilisez WordPress)
Combiner les requêtes (minifier les fichiers, autrement dit les combiner en un seul). Par exemple, vous pouvez assembler six petits fichiers CSS en un seul fichier CSS plus volumineux. Il se chargera même plus rapidement.
Réduire la complexité des scripts (pour réduire le nombre d’appels).
L’optimisation du code en général (HTML, CSS ou Javascript) et des requêtes HTTP en particulier permet une exécution plus rapide et permet de consommer globalement moins de ressources. Un point clé pour un projet numérique responsable !
Optimiser le chargement
Entrer dans le cadre du numérique responsable, c’est également prendre le temps d’optimiser le chargement de votre site. Le temps nécessaire pour charger une page impacte non seulement l’expérience utilisateur mais aussi la consommation d’énergie. Quelques techniques sont clés :
le lazy loading : le chargement de la page au fur et à mesure du défilement permet de chercher les ressources que lorsque c’est nécessaire.
La mise en cache permet aussi de limiter les ressources les plus gourmandes en servant immédiatement les fichiers.
Utilisation des CDN : L’utilisation de réseaux de distribution de contenu (CDN) peut réduire la distance de transfert des données, ce qui peut diminuer aussi la consommation d’énergie.
Finalement, les indicateurs clés pour un projet numérique responsable font également partis des éléments affectant le plus l’expérience de vos utilisateurs. Faire de votre projet, un projet numérique responsable vous permet également d’e faire un projet d’acquérir une interface plus efficace pour vos visiteurs.
2. Quels sont les bons outils pour un projet numérique responsable ?
Note : de très (très) nombreux outils pourraient être présentés dans cette section de cet article. L’objectif n’est pas d’être exhaustif mais plutôt de vous présenter les quelques outils que l’on trouve pas mal et qui vous aideront à réaliser un projet numérique responsable. Si vous n’avez pas le même avis, n’hésitez pas à m’écrire sur LinkedIn pour que nous puissions en discuter !
Analyse du code
SonarQube : SonarQube est un outil d’analyse de qualité du code qui collecte et analyse le code source, fournissant des rapports sur la qualité du code de votre projet. Il combine des outils d’analyse statique et dynamique, permettant de mesurer la qualité de manière continue. SonarQube inspecte et évalue chaque aspect de votre code, offrant un historique consultable du code pour analyser les problèmes : style, défaillances, duplications, manque de couverture de test ou complexité excessive.
Le logiciel analyse le code source sous différents angles, du niveau du module au niveau de la classe, fournissant des valeurs métriques et des statistiques révélant les zones problématiques nécessitant des améliorations. SonarQube garantit également la fiabilité du code, la sécurité de l’application et réduit la dette technique en rendant votre base de code propre et maintenable. Il prend en charge 27 languages différentes, dont le C, le C++, Java, JavaScript, PHP, GO, Python, et bien plus encore. SonarQube propose également une intégration CI/CD et fournit des retours lors de la revue de code avec l’analyse des branches et la décoration des demandes d’extraction.
Evidemment, vous pouvez aussi tester EcoCode ou des outils plus classiques comme Jenkins par exemple.
Analyse des performances techniques (côté client)
Pour mesurer ces indicateurs, des outils comme Google PageSpeed Insights, GTmetrix, ou encore WebPageTest peuvent être utilisés. Ils fournissent des analyses détaillées des pages web et offrent des recommandations pour améliorer leur performance et réduire leur impact écologique. En plus de ces outils, des initiatives spécifiques, comme le Green Web Foundation, peuvent fournir des informations sur l’éco-responsabilité des services d’hébergement web.
Pour estimer la consommation d’électricité et l’émission de GES
Ecoindex.fr : L’écosystème EcoIndex met à disposition plusieurs outils permettant de calculer un score en s’appuyant sur les bonnes pratiques définies par le “Collectif numérique responsable”.
Des extensions pour les navigateurs existent aussi. Par exemple : Green IT. Découvrez notre article dédié à Green IT ici !
Tableau récapitulatif des indicateurs :
Les statistiques doivent idéalement être analysées pour chaque page de votre site. Voici une proposition de tableau synthétique pour un suivi efficace de votre site ou application
URL de la page
Unités
Source de la donnée
Poids de la page
Nombre d’éléments du DOM
Nombre de requête
Temps de chargement (de la page)
Estimation GES
Électricité consommé
Conclusion
Chercher à réduire l’impact écologique de ses assets numériques, est une démarche que nous encourageons vivement ! Mais c’est aussi une démarche qui permet simplement d’optimiser son site web et donc améliorer sa performance commerciale (de nombreuses études démontrent la corrélation entre la vitesse d’un site et l’acte d’achat par exemple).
Evidemment, cela ne résoudra pas le réchauffement climatique (même si cela nous désole) mais si chacun de nos actes devient à chaque fois un peu plus responsable, peut-être arriverons nous à faire quelque chose ? Finalement, un projet numérique responsable c’est avant tout un projet plus efficace. Votre temps et votre investissement ne seront que mieux récompensés.
Voyons ce que TheCodingMachine peut faire pour vous...×
Let's see what TheCodingMachine can do for you...×