Imaginez une application mobile révolutionnaire, une sorte de génie numérique qui réalise vos désirs les plus fous : elle vous prépare le café matinal, planifie votre journée, vous maintient connecté•e avec vos proches, effectue vos courses, et même – pourquoi pas – elle pourrait se rendre au travail à votre place lorsque la fatigue se fait trop sentir ! Après plusieurs mois d’utilisation, elle est devenue votre indispensable compagnon numérique.
Pourtant, un jour, sans crier gare, votre connexion internet vous abandonne, le wifi se met en grève et vous vous retrouvez coincé•e avec un réseau EDGE des plus chaotiques. La machine à café refuse d’obéir, votre agenda se perd dans les méandres du cyberespace, les conversations avec vos proches ont disparu et vos courses ne se commandent plus automatiquement. Un écran blanc s’affiche, suivit d’un chargement infini… bref, l’application cesse de répondre… Tout semble s’effondrer à cet instant précis. Une application si merveilleuse, si vitale, devient soudainement inutilisable à cause d’une simple coupure d’internet ?
Découvrons ensemble comment cette application prétendument « géniale » peut réellement le devenir, même lorsque la connexion internet flanche.
L’expérience utilisateur au coeur des applications
Lors de la création d’une application mobile, tout tourne autour de l’expérience vécue par les utilisateurs•rices. C’est ce qui guide chaque étape de réflexion. L’exemple précédemment évoqué est extrême, mais il illustre de manière saisissante les conséquences d’une défaillance du réseau. Cependant, des situations plus concrètes peuvent également mettre en lumière l’importance cruciale du mode hors ligne.
Imaginons une application où des employés•ées doivent badger un QR Code pour débuter des missions à des endroits spécifiques. Si ces QR Codes sont placés dans des zones de réseau instable, comme des zones géographiques mortes ou des bâtiments avec une mauvaise réception, l’utilisateur•rice se retrouvera confronté•e à la frustration de voir l’application, vantée par ses supérieurs, dysfonctionner.
Les connexions internet instables ne se limitent pas uniquement à des situations isolées. Elles peuvent provenir de divers facteurs, tels que des connexions limitées (dans des hôtels ou à l’étranger), des pannes de courant, des conditions météorologiques extrêmes, ou même une mauvaise couverture de la part du fournisseur de services.
Lorsque nous entreprenons la création d’une application mobile, la considération de la perte ou de la mauvaise qualité de connexion doit être au cœur de chaque fonctionnalité développée. Cela garantit une expérience optimale de l’application, même lorsque les conditions de connectivité sont difficiles.
Le mode hors ligne vous dites ?
Implémenter le mode hors ligne dans une application mobile permet à celle-ci de continuer à fonctionner et à offrir certaines fonctionnalités, même lorsque l’appareil n’a pas ou peu d’accès à Internet. Cependant, assurer une utilisation continue de l’application ne relève pas de la magie. Certaines fonctionnalités ne peuvent pas fonctionner sans connexion internet, mais il existe diverses façons de gérer la perte de connexion, comme nous l’illustrerons ci-dessous.
Par exemple, une messagerie en temps réel nécessite une connexion active pour fonctionner pleinement. Si ce sujet vous intéresse, nous avons un article ici : Le temps réel en web, quand chaque seconde compte ! Toutefois, même dans ces cas, des solutions alternatives peuvent être envisagées pour améliorer l’expérience utilisateur•rice malgré l’absence de connexion.
Comment améliorer concrètement l’expérience utilisateur•rice grâce au mode hors ligne ?
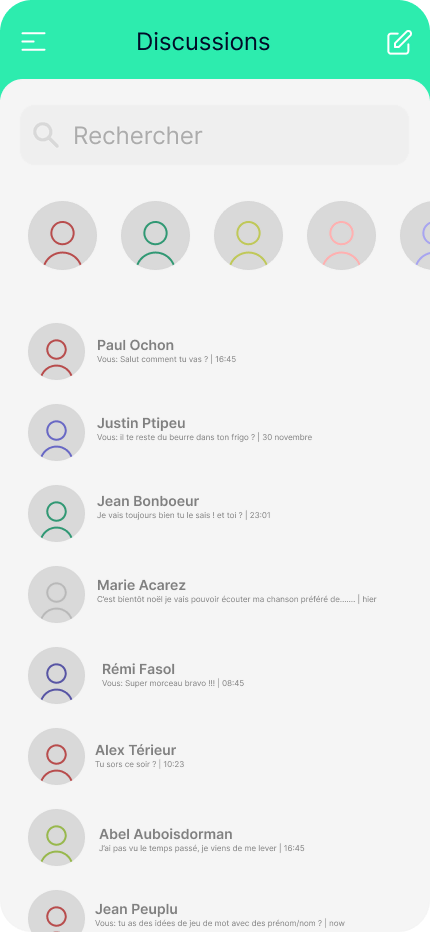
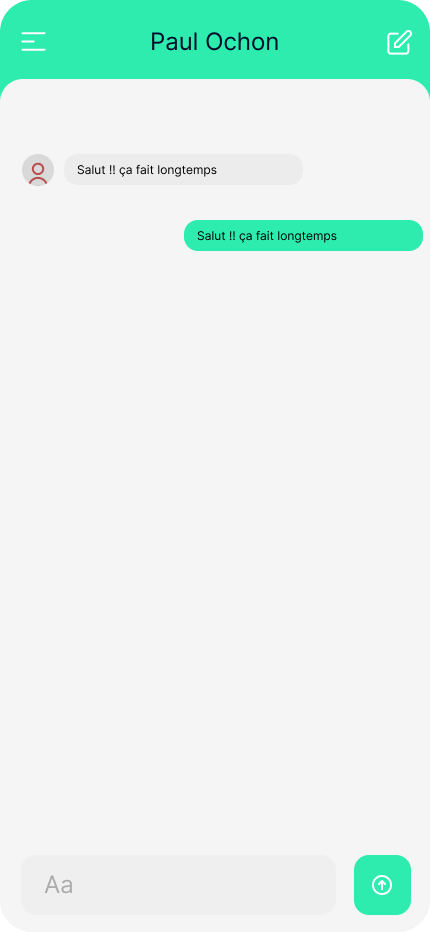
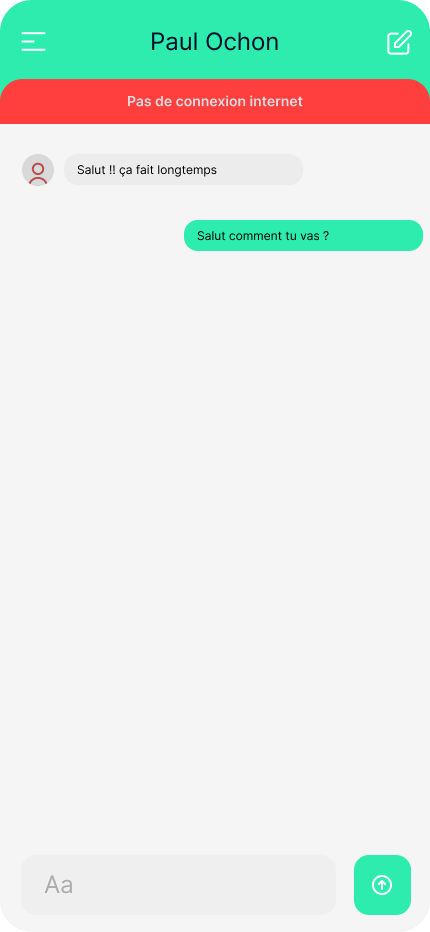
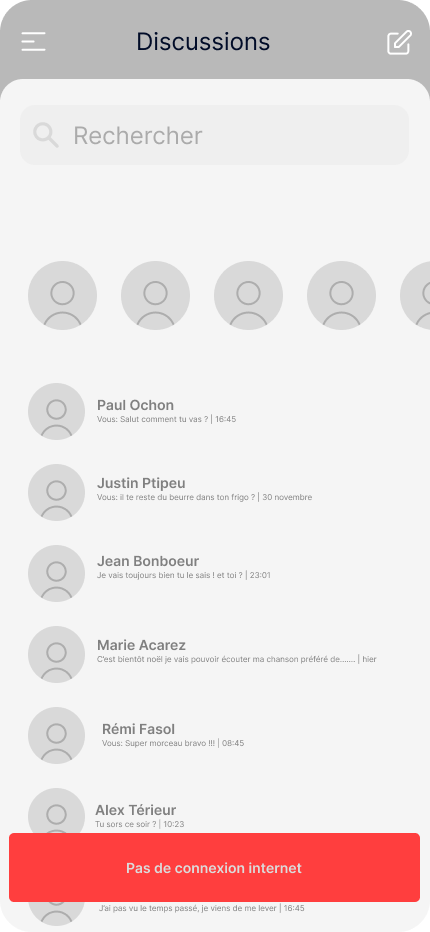
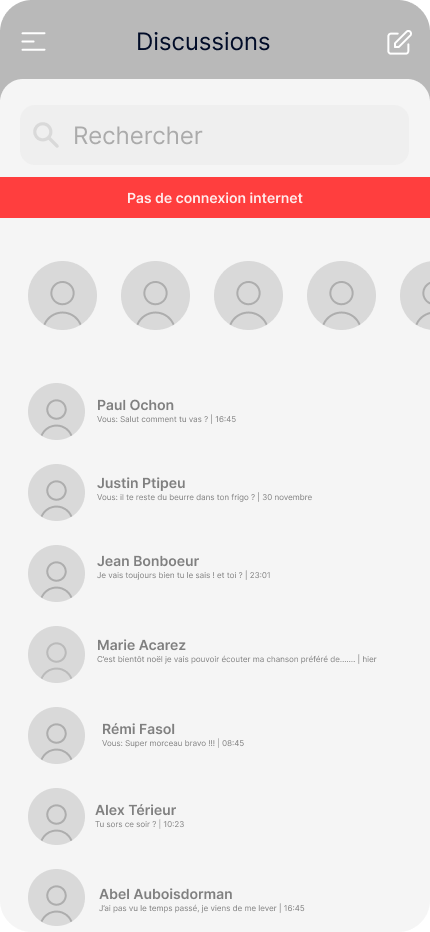
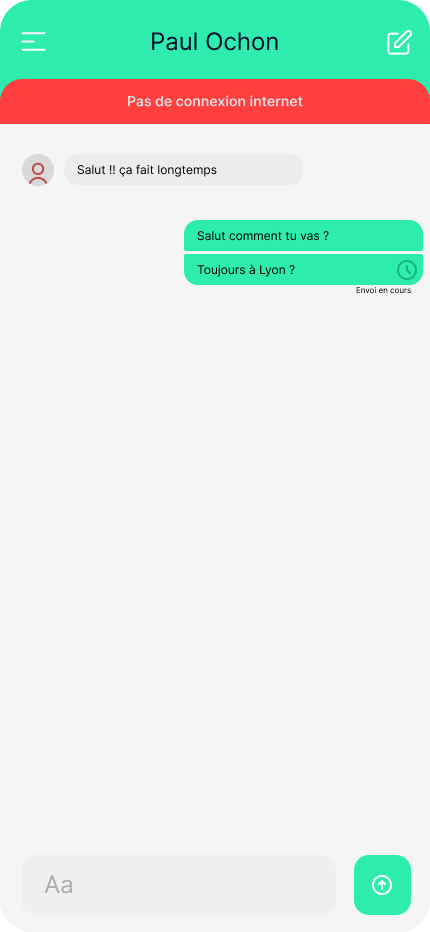
Prenons pour exemple une application de messagerie instantanée élémentaire. Dans cette application, le premier écran présente la liste des conversations (1), et dès qu’on sélectionne l’une d’elles, l’ensemble de la conversation s’affiche (2).
Si nous n’avions pas pris en compte les futurs utilisateur•rices, nous aurions supposé que tout fonctionnait parfaitement : le premier écran aurait simplement envoyé une requête via le réseau Internet pour récupérer mes conversations. Une fois la réponse obtenue, elle aurait été affichée dans l’application et voilà, affaire réglée. Cependant, le problème survient si, pour l’une des raisons évoquées précédemment, le réseau venait à disparaître. Dans cette situation, l’application continuerait à charger indéfiniment jusqu’à ce qu’un message d’erreur peu explicite apparaisse du genre “Network error”…
Voyons comment le mode hors ligne peut concrètement enrichir l’expérience utilisateur•rice dans ce contexte spécifique :
La notification visuel
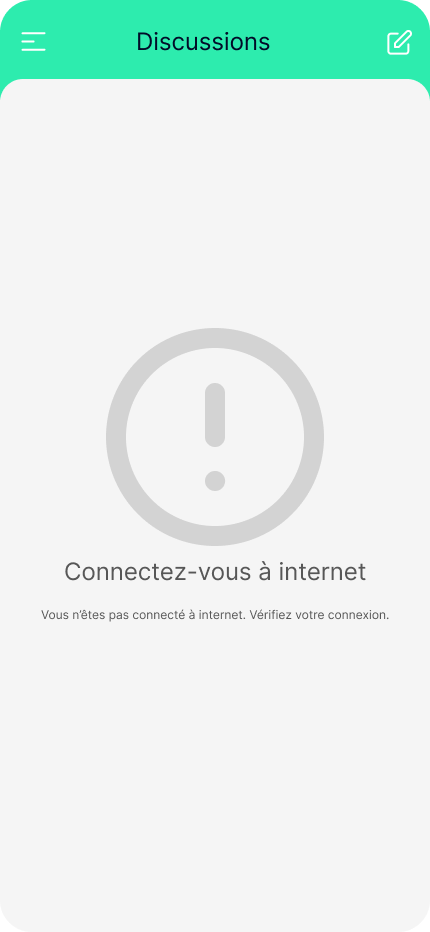
La première étape consiste à informer l’utilisateur•rice que son expérience est altérée et pourquoi. Cela permet d’éviter les frustrations découlant de l’utilisation d’une application dans des conditions où elle ne peut fonctionner pleinement. Nombreuses sont les applications qui ne peuvent pas être utilisées à leur plein potentiel hors connexion. C’est le cas de YouTube, qui bloque la lecture des vidéos, ou de Messenger, qui affiche un bandeau en haut de l’application pour signaler l’absence de connexion. Pour autant, personne n’a l’impression que l’application “bug”.
En ce qui concerne notre application de messagerie, concentrons-nous sur la première interface : les conversations sont stockées dans une base de données, mais je ne peux pas accéder à cette base sans connexion Internet. Ainsi, je pourrais envisager d’afficher une erreur claire et précise, à la manière de YouTube, décrivant explicitement le problème rencontré :
Il est crucial d’employer des termes appropriés, simples et compréhensibles, sans recourir à un langage technique, pour garantir une explication claire, directe et précise.
Ne pas bloquer l’utilisateur
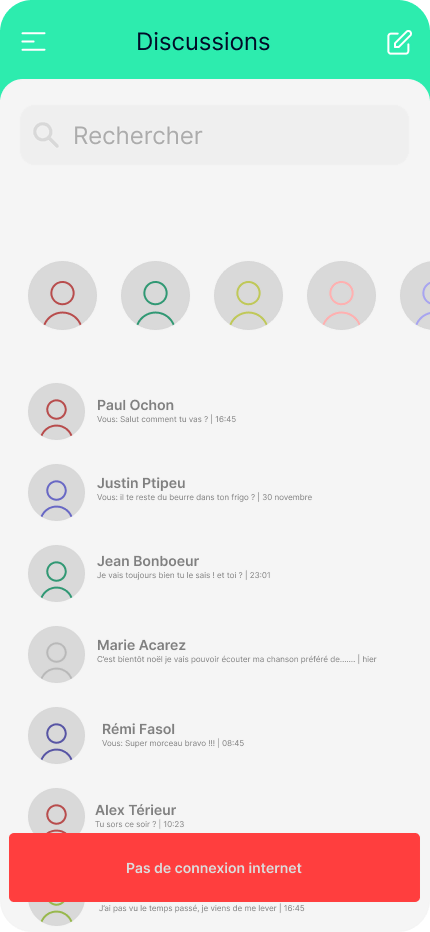
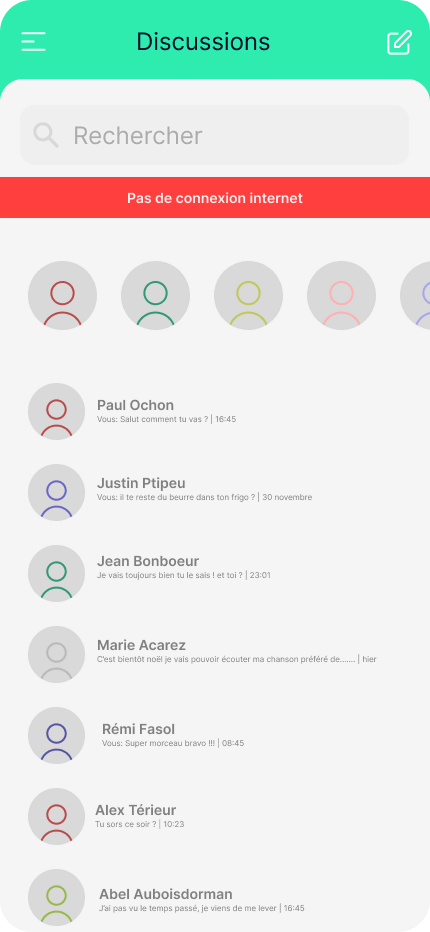
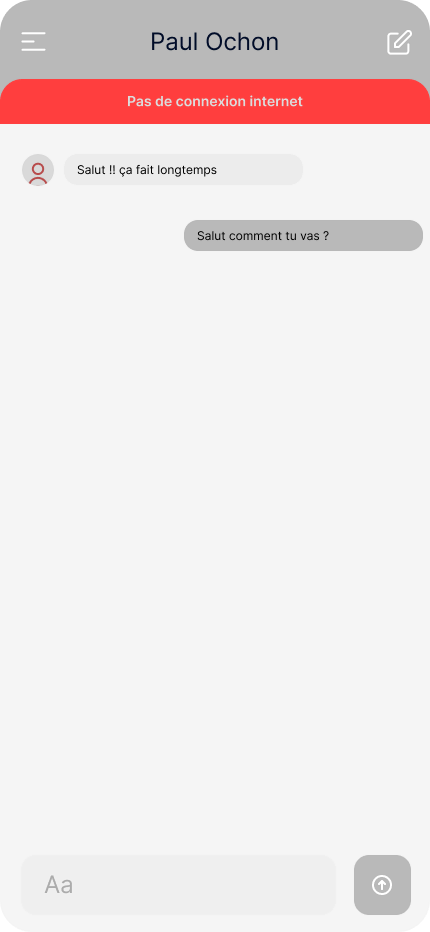
Dans le contexte de notre application, la notification précédente bloque entièrement l’accès aux discussions (sans affecter le reste de l’application). Cependant, une meilleure approche permettrait d’offrir une notification moins intrusive et agressive, tout en donnant à l’utilisateur•rice la possibilité d’accéder à quelques fonctionnalités supplémentaires comme pouvoir visualiser des conversations.
Dans le cas d’une connexion instable, il est préférable d’utiliser une notification visuelle impactante mais non intrusive lorsque la connectivité réseau fluctue plutôt qu’un effet stroboscopique entre l’écran chargé et l’écran d’erreur.
De plus, lors du chargement des données, il est préférable d’éviter les chargements en plein écran qui immobilisent l’utilisateur•rice. À la place, on privilégie les “écrans squelettes” (skeleton loader), qui représentent des espaces (souvent animés) réservés pour les informations en cours de chargement. Un écran squelette imite la structure et l’apparence de la vue complète, donnant ainsi un aperçu visuel du contenu en attente de chargement dans chaque bloc, que ce soit une image, du texte ou tout autre type d’information.
Il est toujours possible d’offrir une façon originale de notifier l’utilisateur que l’application passe en mode hors ligne en offrant un nouveau visuel à l’application. Par exemple passer l’application en noir et blanc :
Le stockage
Pour résoudre la problématique précédente, une solution consisterait à stocker localement les 10 derniers messages des 10 dernières conversations sur le téléphone. Ainsi, même en cas de connexion faible ou inexistante, l’utilisateur•rice ne serait pas bloqué•e.
Le stockage est une solution efficace pour améliorer l’expérience utilisateur en cas de perte de connexion. Dans notre application, elle permettrait aux utilisateurs•rices de voir les derniers messages d’une conversation comme par exemple ou se situe l’adresse du restaurant où ils ont rendez-vous même si le réseau les a abandonnés.
Cette approche assure une utilisation continue et pratique de l’application, malgré les éventuelles perturbations de la connectivité.
Soumission différée
Une autre façon d’améliorer l’expérience utilisateur est de lui offrir la possibilité d’écrire et d’envoyer un message même en l’absence de connexion. L’utilisateur•rice peut accéder à une conversation, y rédiger un message et l’envoyer. Une notification visuelle claire indiquera que ce message sera transmis dès que le réseau sera rétabli. Cette fonctionnalité garantit une continuité d’utilisation de l’application sans interruption, même lorsque la connexion est instable.
C’est tout ?
Evidemment que non ! En effet, de nombreuses méthodes permettent d’améliorer considérablement une application mobile même lorsque la connexion réseau n’est pas optimale. Nous avons exploré les principaux éléments à prendre en compte lors de la conception d’une application de qualité autour d’un exemple des plus simple. Toutefois, les solutions sont variées et l’innovation persiste à découvrir des techniques avancées pour enrichir davantage l’expérience utilisateur•rice.
Il faut garder en tête que, faire simple et comprendre ce que l’utilisateur•rice va utiliser ou pas est le plus important. Nous pourrions prendre l’exemple d’applications plus complexes comme Google Docs où il est possible de collaborer sur un document en hors connexion et où la logique de fusion des versions à été faite de la plus simple des manières. En effet, le cas d’utilisation reste des moins fréquent, les équipes de Google ont donc opté pour une solution “simple” qui est de fusionner l’ensemble du texte modifié par les auteurs•rices au risque que le texte devienne incompréhensible. Il suffira ensuite de reformuler l’ensemble. Cela évite les pertes de contenu, simplifie le code source et sa compréhension et optimise le temps de développement pour répondre à de vraies problématiques utilisateurs•rices.
Les possibilités sont vastes, mais chaque innovation requiert une exigence, une expertise technique et une connaissance des besoins utilisateur•rice. Chez TheCodingMachine, nous aimons relever ces défis et nous y confrontons avec passion et expertise !
Que peut-on en conclure ?
Le mode hors ligne représente un défi technique avec ses petits challenges si l’on souhaite innover. Cependant, arriver à produire une application de qualité qui répond aux exigences actuelles des consommateurs•rices d’application mobile n’est pas difficile tant que ces derniers•ères sont placés•ées au cœur de la conception.
Auteur: Jérémy Dollé