LangChain est un framework qui facilite le développement d’applications utilisant des modèles de langage naturel (LLM). Depuis son lancement, il a rapidement gagné en popularité : plus de 87 000 étoiles sur GitHub (à comparer aux 77 000 étoiles de Laravel, le framework PHP le plus populaire !). Ce succès s’explique par sa capacité à simplifier l’intégration des modèles NLP dans plein de projets.
Qu’est-ce que LangChain ?
LangChain est un framework open-source conçu pour orchestrer et gérer les modèles de langage naturel. Il permet aux développeurs de créer des chaînes complexes de traitements linguistiques, en intégrant divers modèles et outils. LangChain est particulièrement adapté pour optimiser les workflows de traitement du langage naturel.
Fonctionnalités principales
Orchestration de modèles : LangChain permet de combiner plusieurs modèles NLP en une seule chaîne de traitement, optimisant ainsi les flux de travail et les résultats finaux.
Modularité : Le framework est conçu de manière modulaire, permettant aux développeurs d’ajouter ou de remplacer des composants sans affecter l’ensemble de la chaîne.
Support multi-plateforme : LangChain est compatible avec diverses plateformes et frameworks, facilitant son intégration dans des environnements existants.
Personnalisation : Les utilisateurs peuvent personnaliser les chaînes de traitement selon leurs besoins spécifiques, en ajustant les paramètres et en ajoutant des modules supplémentaires.
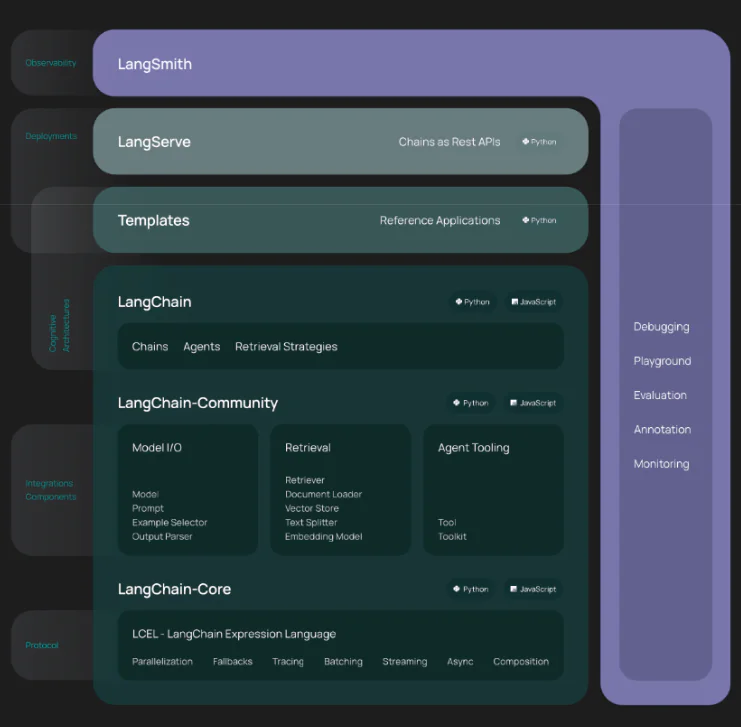
Concrètement, le framework se compose des bibliothèques open source suivantes :
langchain-core : abstractions de base et langage d’expression LangChain.
langchain-community : intégrations tierces.
Packages partenaires (par exemple langchain-openai, langchain-anthropic, etc.) : certaines intégrations ont été divisées en leurs propres packages qui dépendent uniquement de langchain-core.
langchain : chaînes, agents et stratégies de récupération qui constituent l’architecture cognitive d’une application.
LangGraph : créez des applications multi-acteurs robustes et dynamiques avec des LLM en modélisant les étapes sous forme d’arêtes et de nœuds dans un graphique.
LangServe : permet de déployer des chaînes LangChain en tant qu’API REST (Le framework python sous jacent est Fast API)
LangSmith : une plate-forme de développement qui vous permet de déboguer, tester, évaluer et surveiller les applications LLM (Notamment afin de suivre les tokens et les coûts associés)
Pourquoi utiliser LangChain ?
Réduction du temps de développement
LangChain simplifie la création et la gestion des workflows de traitement du langage naturel. En permettant aux développeurs de combiner différents modèles et outils en une seule chaîne, il réduit la complexité et le temps nécessaire pour développer des applications NLP.
Flexibilité
Grâce à ses modules, LangChain offre une grande flexibilité. Les développeurs peuvent facilement ajouter de nouveaux composants ou les remplacer pour répondre aux besoins de leurs projets. Par exemple, vous pouvez utiliser un modèle pour l’analyse syntaxique, un autre pour la génération de texte, et un troisième pour la traduction.
Intégration
LangChain est conçu pour s’intégrer facilement avec les infrastructures existantes. Que vous utilisiez des plateformes de cloud computing, des bases de données ou d’autres outils de NLP, LangChain peut être intégré sans effort, améliorant ainsi la productivité et l’efficacité.
Performances
En permettant une orchestration efficace des modèles, LangChain optimise les performances des applications NLP. Les développeurs peuvent tirer parti de la puissance combinée de plusieurs modèles, améliorant ainsi la précision et la pertinence des résultats.
Cas d’utilisation de LangChain
Génération de contenu
LangChain peut être utilisé pour automatiser la génération de contenu. En combinant des modèles de génération de texte avec des outils d’analyse de sentiment et de style, les développeurs peuvent créer des articles, des descriptions de produits, et même des scripts de chatbots.
Analyse de données
L’analyse de données textuelles est une autre application importante. En utilisant des modèles d’extraction d’informations, de classification de texte, et d’analyse de sentiment, LangChain permet de transformer des données brutes en informations exploitables.
Traduction automatique
Ce framework peut aussi être utilisé pour la traduction automatique. En combinant des modèles de traduction avec des outils de correction grammaticale et de reformulation, il offre des traductions assez précises.
Chatbots et assistants virtuels
LangChain permet de développer des chatbots et assistants virtuels de manière très rapide, en combinant des modèles de compréhension du langage naturel avec des modules de génération de réponses.
Les modules les plus intéressants !
Intégration des bases de données
Un module particulièrement prometteur de LangChain est le SQLDatabase, qui utilise SQLAlchemy pour permettre aux modèles NLP d’interagir avec les bases de données relationnelles. Ce module génère des requêtes SQL à partir de commandes en langage naturel, optimise ces requêtes pour une performance maximale et formate les résultats de manière compréhensible. Cela simplifie grandement l’extraction et l’analyse des données stockées, rendant les analyses accessibles à tous les niveaux de compétence technique.
… et nous publierons très prochainement un autre article sur ce sujet ! #Teasing
Autres modules prometteurs de LangChain
En plus de SQLDatabase, LangChain propose d’autres modules prometteurs, même si certains sont encore en phase bêta :
La possibilité de créer des Tools (ou modules) pour interagir notamment avec des API créant ainsi des tâches très spécifiques. Par exemple, les mathématiques sont très mal gérées dans les IA génératives… Ou bien si vous avez besoin d’envoyer un email.
Les tools relatif à Google (Drive, Finance, Lens, etc.) qui permettent une connexion au API Google depuis Langchain ;
Le Tools Gitlab et/ou Github permettant d’automatiser intelligemment des actions telles que la gestion de dépôts, les révisions de code, et les déploiements, améliorant ainsi l’efficacité des workflows DevOps..
Conclusion
LangChain se révèle être un framework hyper intéressant si vous souhaitez intégrer l’IA dans vos projets. Grâce à sa modularité, sa flexibilité, et ses capacités d’orchestration, LangChain vous permet de développer rapidement des fonctionnalités telles que : la génération de contenu, l’analyse de données, ou la création de chatbots.
De plus, avec des modules comme SQLDatabase, il facilite l’intégration des bases de données SQL et l’orchestration de tâches complexes, permettant des interactions plus simples avec les données.
Lors d’un échange avec l’un de nos clients, la question de l’automatisation des requêtes SQL est rapidement devenue un sujet de discussion. Notre client nous a fait part du gain de temps potentiel en adoptant une approche où les requêtes SQL pourraient être générées à partir de questions formulées en langage naturel. Intrigués par cette perspective, nous avons décidé d’explorer cette piste.
Afin d’utiliser des LLM (Grand modèle de langage) tout en ayant une structure modulaire et évolutive, notre choix s’est naturellement porté sur le framework Langchain qui semble être l’étoile montante des frameworks IA.
Langchain est une bibliothèque qui utilise le traitement du langage naturel (NLP) qui permet en partie de convertir des phrases en requêtes SQL. Cette approche promet de simplifier l’accès aux données pour les utilisateurs non techniques, tout en améliorant l’efficacité des processus d’analyse de données.
Chez The Coding Machine, nous avons exploré différentes options afin d’automatiser et simplifier nos workflows liés à la gestion des données, notamment dans le cas de multiples statistiques sur une base de données client. Après avoir examiné les avantages potentiels de Langchain, nous avons décidé de mettre ce framework à l’épreuve en utilisant la base de données open source Chinook. Cet article a pour ambition de vous guider à travers notre expérience, en détaillant comment nous avons configuré notre environnement de travail avec Google Colab et Jupyter Notebook.
Notre objectif est de partager cette expérience afin que d’autres puissent tirer parti de ces outils pour améliorer leurs propres processus d’analyse et de gestion des données. Que vous soyez analyste de données, ingénieur ou simplement curieux des nouvelles technologies, cet article vous fournira des outils pratiques pour optimiser votre utilisation des bases de données.
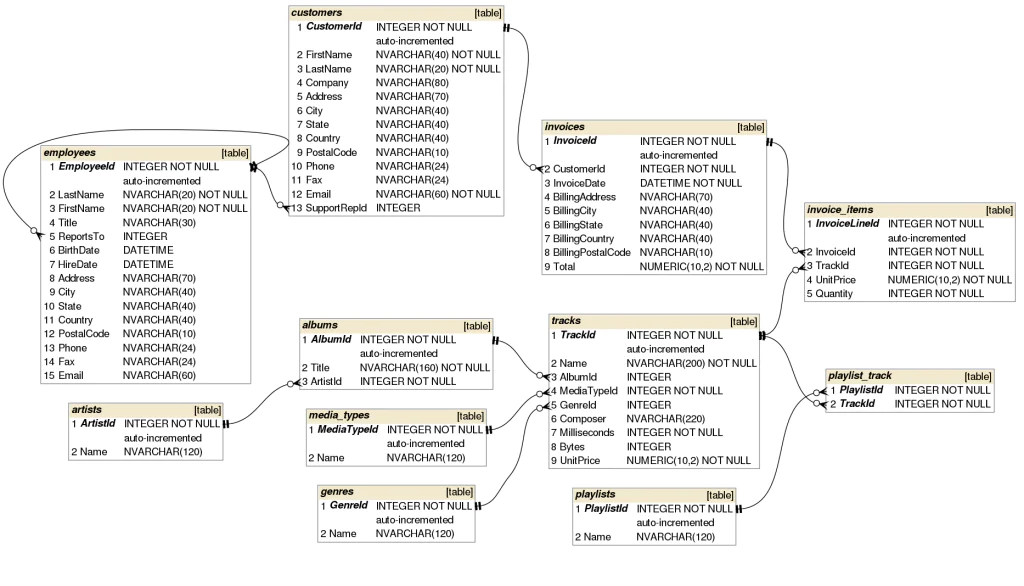
Chinook_DB est une base de données open source largement utilisée dans l’enseignement et les exemples pratiques de gestion de bases de données relationnelles. Initialement conçue pour représenter un magasin de musique en ligne, Chinook_DB offre une structure de données réaliste et plus ou moins complexe, idéale pour simuler des scénarios réels d’interrogation et d’analyse de données.
Cette base de données comprend plusieurs tables interconnectées représentant divers aspects d’une entreprise de vente de musique. Voici quelques-unes des principales tables et leurs relations :
Albums : Contient des informations sur les albums disponibles à la vente.
Artistes : Liste des artistes associés à chaque album.
Clients : Informations sur les clients qui ont acheté des albums.
Commandes : Détails de chaque commande effectuée par les clients.
Pistes audio : Liste des pistes audio disponibles à la vente, avec des informations telles que le nom, la durée et l’album auquel elles appartiennent.
Employés : Détails sur les employés de l’entreprise.
Chinook_DB est structurée de manière à refléter les relations typiques entre les entités dans une plateforme e-commerce de musique.
2. Utilité de Chinook_DB
Chinook_DB est particulièrement utile pour les démonstrations et les apprentissages pratiques dans le domaine de la gestion de bases de données relationnelles. En raison de sa structure bien définie et de ses données réalistes, Chinook_DB permet aux utilisateurs d’explorer des requêtes SQL et de simuler divers scénarios d’analyse de données. Dans le cadre de notre exploration de Langchain et la génération de requêtes SQL, Chinook_DB offre un environnement idéal pour illustrer l’efficacité et la précision de Langchain dans la transformation des questions en langage naturel en requêtes SQL fonctionnelles.
3. Modèle de données
Environnement de développement
La mise en place d’un environnement de développement est important afin d’explorer efficacement les capacités de Langchain dans la génération de requêtes SQL à partir de langage naturel. Dans cette partie, nous détaillerons les étapes pour configurer votre environnement de travail avec Google Colab et Jupyter Notebook, deux plateformes populaires pour le développement interactif en Python.
1. Choix de l’environnement
Google Colab (cloud) : Google Colab est un service de notebook Jupyter hébergé par Google qui permet d’écrire et d’exécuter du code Python dans le cloud, sans nécessiter de configuration locale. Il offre un accès gratuit à des processeurs et de la RAM pour des calculs intensifs, ce qui peut être avantageux pour le traitement de données volumineuses.
Jupyter Notebook (local) : Jupyter Notebook est une application web open source qui vous permet de créer et de partager des documents contenant du code, des équations, des visualisations et du texte explicatif. Il est idéal pour le développement interactif et l’analyse de données.
En optant pour Google Colab et Jupyter Notebook, nous avons choisi des outils qui non seulement facilitent le développement et le débogage, mais qui améliorent aussi la documentation, la collaboration. Ces plateformes offrent des avantages significatifs par rapport à l’utilisation de fichiers Python séparés, rendant le processus de test et de mise en œuvre de Langchain plus efficace et plus convivial.
2. Installation des outils
Pour commencer, assurez-vous d’avoir un compte Google pour utiliser Google Colab et d’avoir installé Python sur votre machine pour Jupyter Notebook. Voici les étapes générales pour configurer votre environnement :
Google Colab
1. Ouvrez un navigateur web et accédez à Google Colab 2. Créez un nouveau notebook ou importez un notebook existant depuis Google Drive ou GitHub
Avantages :
– Python est disponible en dernière version et il est très simple d’installer des librairies (“!pip install langchain” par exemple)
– Pas besoin d’un environnement local
– Partage et collaboration simplifié
Jupyter Notebook
1. Installez Jupyter Notebook en utilisant pip si ce n’est pas déjà fait (Les frameworks populaire tel que JetBrains ou Visual Studio ont des modules pour Jupyter) 2. Jupyter pourra alors être complètement intégré à votre IDE
Avantages :
– Pas de dépendance au cloud
– Moins de déconnexion intempestive
– Un environnement local plus souple et maîtrisable
Pratique : Mise en place technique
Dans cette partie, nous allons voir comment utiliser Langchain concrètement étape par étape. L’objectif de cet article est d’arriver à un résultat où nous pourrons poser une question naturelle et le modèle devra nous répondre une requête SQL fonctionnelle puis l’exécuter directement afin d’avoir le résultat.
Notez que nous allons aborder une infime partie de ce que propose Langchain cependant nous ne pouvons pas couvrir la totalité dans cet article, si ce framework vous intéresse, rendez-vous sur la documentation officielle.
⚠️ Attention ⚠️ Comme le précise Langchain, connecter une base de données de production à un LLM n’est pas sans risque, des instructions DML pourraient sans doute être exécutées par une personne malveillante. Il est donc très important de mettre en place une stratégie de sécurité : – Dupliquer la base de données avec une lecture seule (Master / slave par exemple) – Anonymiser les informations critiques tels que les users (Données personnelles, mots de passes, etc.) ou les API key
Avant d’aller plus loin, voici les éléments que nous allons aborder :
Un toolkit est un ensemble de tools qui permettent d’exécuter un groupe de fonction mis à disposition. Dans notre exemple, le Toolkit SQL Database va nous permettre d’avoir un ensemble de fonctions pré paramétré et notamment avec des prompts déjà mis en place.
L’agent, dans notre contexte, est un module proposé par Langchain qui agit comme un intermédiaire entre l’utilisateur et la base de données. Il est capable de comprendre des requêtes en langage naturel, de les traduire en requêtes SQL en suivant les fonctions mise à disposition par le Toolkit.
LangSmith va nous permettre d’avoir une visibilité sur l’utilisation de Langchain, nombres de tokens par requête, coûts, organisation des fonctions, input, output, etc. Cela permet de déboguer plus facilement du code.
Pour la suite de cet article nous allons utiliser Google Colab, ce qui permettra de vous partager le Notebook de cet article
Installation des paquets
Cette ligne installera tous les paquets nécessaires au code que nous allons utiliser.
Note : Le ! devant pip dans Google Colab est utilisé pour exécuter des commandes de shell directement depuis une cellule du notebook. En mettant !pip, vous dites à Google Colab d’exécuter la commande pip
Variable d’environnement
Google Colab met à disposition un gestionnaire de clés, vous pouvez donc renseigner de façon sécurisée vos secrets et les appeler directement dans le code.
# Getting env variables from Google Colab secrets
from google.colab import userdata
import os
# OpenAI key
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
# LangSmith
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = userdata.get('LANGCHAIN_API_KEY')
Initialisation de la base de données
Nous allons vérifier que la base de données existe car Colab supprime très régulièrement les données. Si vous souhaitez persister vos données, regardez l’intégration Colab de Google Drive.
from langchain.sql_database import SQLDatabase
db_path = "[path]/chinook_data.db"
if not os.path.exists(db_path):
raise FileNotFoundError("Database file not found.")
db = SQLDatabase.from_uri(f"sqlite:///{db_path}")
Nous allons maintenant instancier notre classe Chat model afin de traiter la demande de l’utilisateur. LangChain va maintenant nous permettre de créer un agent, celui-ci pourra appeler à de multiples reprises le chat model ainsi que la base de données.
from langchain_openai import ChatOpenAI
from langchain_community.agent_toolkits import create_sql_agent
# Instanciate the class ChatOpenAI
chat_model = ChatOpenAI(model_name='gpt-4o', temperature=0.5)
# Create a new sql agent
agent_executor = create_sql_agent(model, db=db, agent_type="openai-tools", verbose=True)
# Run the user query
agent_executor.invoke("How much artists are in the db ?")
Nous sommes maintenant prêts à réaliser quelques tests. Le paramètre “verbose” va nous permettre de consulter le chemin parcouru par notre Toolkit pour arriver à un résultat. Notez qu’il est également possible (et recommandé) de consulter ce parcours sur LangSmith.
Nous allons prendre pour exemple un cas simple pour l’instant, nous voulons savoir combien d’artistes sont présents dans la base de données.
Notre question sera donc : How many artists are in the db ?
Note : Les tests semblent montrer que les requêtes peuvent être écrites en Français mais nous le ferons en anglais dans cet article
La question est simple, si nous reprenons notre modèle de données, il n’y aucune relation, voici donc la requête :
SELECT COUNT(*) FROM artists;
Lançons maintenant le script :
> Entering new SQL Agent Executor chain...
Invoking: `sql_db_list_tables` with `{}`
albums, artists, customers, employees, genres, invoice_items, invoices, media_types, playlist_track, playlists, tracks
Invoking: `sql_db_schema` with `{'table_names': 'artists'}`
CREATE TABLE artists (
"ArtistId" INTEGER NOT NULL,
"Name" NVARCHAR(120),
PRIMARY KEY ("ArtistId")
)
/*
3 rows from artists table:
ArtistId Name
1 AC/DC
2 Accept
3 Aerosmith
*/
Invoking: `sql_db_query_checker` with `{'query': 'SELECT COUNT(*) as artist_count FROM artists;'}`
```sql
SELECT COUNT(*) as artist_count FROM artists;
```
Invoking: `sql_db_query` with `{'query': 'SELECT COUNT(*) as artist_count FROM artists;'}`
[(275,)]There are 275 artists in the database.
> Finished chain.
{
'input': 'How much artists are in the db ?',
'output': 'There are 275 artists in the database.'
}
Le résultat est cohérent et celui attendu. Nous pouvons voir les différentes fonctions utilisées par notre toolkit. Pour aller plus loin, allons jeter un oeil sur LangSmith.
Sans rentrer dans les détails, cela fera peut être l’objet d’un article sur ce sujet, mais nous pouvons constater que 4 différentes fonctions avec des tâches bien précises sont appelées.
1. sql_db_query
Cette fonction a pour objectif de recevoir une requête SQL correcte (syntaxiquement parlant) et de l’exécuter. Dès lors que l’exécution de celle-ci renvoie une erreur, le prompt précise qu’il doit essayer de réécrire la requête.
Si un problème de “Unknown column” est présent, alors il faut rappeler la fonction “sql_db_schema” afin de vérifier le schéma.
Dans le cas où l’exécution de la requête est un problème de syntaxe SQL, alors il rappelle “sql_db_query_checker” et tente de réécrire la requête.
2. sql_db_schema
Cette fonction a pour objectif de recevoir en entrée une liste de tables séparées par des virgules. La sortie est le schéma et les lignes d’exemples des tables de l’entrée.
Une vérification peut être faite afin de vérifier que les tables existent en appelant “sql_db_list_tables”
3. sql_db_list_tables
Renvoie toutes les tables de la base de données.
4. sql_db_query_checker
Cette fonction est appelée avant l’exécution de la requête SQL afin de vérifier sa syntaxe.
Note : Il faut bien comprendre ici que les Tools (ou fonctions) sont appelées par le LLM. Il est capable de comprendre une question et/ou un problème et donc d’appeler un tool en fonction du problème rencontré.
Allons un peu plus loin maintenant, si nous analysons notre modèle de données, l’idéal serait d’avoir une demande qui recherche dans plus de trois tables différentes pour ajouter un peu de complexité.
Imaginons que nous souhaitions connaître les clients les plus éclectiques, cherchons ceux qui ont acheté des pistes dans plus de 9 genres musicaux différents et calculons combien ils ont dépensé au total. Idéalement, nous souhaiterions avoir les clients avec le plus de genres affichés en premier.
Voici le prompt : Identify customers who purchased tracks from more than nine different genres, calculate the total amount spent by these customers and sort the result by highest number of genre
Voici l’output de l’agent :
> Entering new SQL Agent Executor chain...
Invoking: `sql_db_list_tables` with `{}`
albums, artists, customers, employees, genres, invoice_items, invoices, media_types, playlist_track, playlists, tracks
Invoking: `sql_db_schema` with `{'table_names': 'customers, genres, invoice_items, invoices, tracks'}`
CREATE TABLE customers (
"CustomerId" INTEGER NOT NULL,
"FirstName" NVARCHAR(40) NOT NULL,
"LastName" NVARCHAR(20) NOT NULL,
"Company" NVARCHAR(80),
"Address" NVARCHAR(70),
"City" NVARCHAR(40),
"State" NVARCHAR(40),
"Country" NVARCHAR(40),
"PostalCode" NVARCHAR(10),
"Phone" NVARCHAR(24),
"Fax" NVARCHAR(24),
"Email" NVARCHAR(60) NOT NULL,
"SupportRepId" INTEGER,
PRIMARY KEY ("CustomerId"),
FOREIGN KEY("SupportRepId") REFERENCES employees ("EmployeeId")
)
/*
3 rows from customers table:
CustomerId FirstName LastName Company Address City State Country PostalCode Phone Fax Email SupportRepId
1 Luís Gonçalves Embraer - Empresa Brasileira de Aeronáutica S.A. Av. Brigadeiro Faria Lima, 2170 São José dos Campos SP Brazil 12227-000 +55 (12) 3923-5555 +55 (12) 3923-5566 luisg@embraer.com.br 3
2 Leonie Köhler None Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 +49 0711 2842222 None leonekohler@surfeu.de 5
3 François Tremblay None 1498 rue Bélanger Montréal QC Canada H2G 1A7 +1 (514) 721-4711 None ftremblay@gmail.com 3
*/
CREATE TABLE genres (
"GenreId" INTEGER NOT NULL,
"Name" NVARCHAR(120),
PRIMARY KEY ("GenreId")
)
/*
3 rows from genres table:
GenreId Name
1 Rock
2 Jazz
3 Metal
*/
CREATE TABLE invoice_items (
"InvoiceLineId" INTEGER NOT NULL,
"InvoiceId" INTEGER NOT NULL,
"TrackId" INTEGER NOT NULL,
"UnitPrice" NUMERIC(10, 2) NOT NULL,
"Quantity" INTEGER NOT NULL,
PRIMARY KEY ("InvoiceLineId"),
FOREIGN KEY("TrackId") REFERENCES tracks ("TrackId"),
FOREIGN KEY("InvoiceId") REFERENCES invoices ("InvoiceId")
)
/*
3 rows from invoice_items table:
InvoiceLineId InvoiceId TrackId UnitPrice Quantity
1 1 2 0.99 1
2 1 4 0.99 1
3 2 6 0.99 1
*/
CREATE TABLE invoices (
"InvoiceId" INTEGER NOT NULL,
"CustomerId" INTEGER NOT NULL,
"InvoiceDate" DATETIME NOT NULL,
"BillingAddress" NVARCHAR(70),
"BillingCity" NVARCHAR(40),
"BillingState" NVARCHAR(40),
"BillingCountry" NVARCHAR(40),
"BillingPostalCode" NVARCHAR(10),
"Total" NUMERIC(10, 2) NOT NULL,
PRIMARY KEY ("InvoiceId"),
FOREIGN KEY("CustomerId") REFERENCES customers ("CustomerId")
)
/*
3 rows from invoices table:
InvoiceId CustomerId InvoiceDate BillingAddress BillingCity BillingState BillingCountry BillingPostalCode Total
1 2 2009-01-01 00:00:00 Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 1.98
2 4 2009-01-02 00:00:00 Ullevålsveien 14 Oslo None Norway 0171 3.96
3 8 2009-01-03 00:00:00 Grétrystraat 63 Brussels None Belgium 1000 5.94
*/
CREATE TABLE tracks (
"TrackId" INTEGER NOT NULL,
"Name" NVARCHAR(200) NOT NULL,
"AlbumId" INTEGER,
"MediaTypeId" INTEGER NOT NULL,
"GenreId" INTEGER,
"Composer" NVARCHAR(220),
"Milliseconds" INTEGER NOT NULL,
"Bytes" INTEGER,
"UnitPrice" NUMERIC(10, 2) NOT NULL,
PRIMARY KEY ("TrackId"),
FOREIGN KEY("MediaTypeId") REFERENCES media_types ("MediaTypeId"),
FOREIGN KEY("GenreId") REFERENCES genres ("GenreId"),
FOREIGN KEY("AlbumId") REFERENCES albums ("AlbumId")
)
/*
3 rows from tracks table:
TrackId Name AlbumId MediaTypeId GenreId Composer Milliseconds Bytes UnitPrice
1 For Those About To Rock (We Salute You) 1 1 1 Angus Young, Malcolm Young, Brian Johnson 343719 11170334 0.99
2 Balls to the Wall 2 2 1 None 342562 5510424 0.99
3 Fast As a Shark 3 2 1 F. Baltes, S. Kaufman, U. Dirkscneider & W. Hoffman 230619 3990994 0.99
*/
Invoking: `sql_db_query_checker` with `{'query': 'SELECT c.CustomerId, c.FirstName, c.LastName, COUNT(DISTINCT t.GenreId) AS GenreCount, SUM(i.Total) AS TotalSpent\nFROM customers c\nJOIN invoices i ON c.CustomerId = i.CustomerId\nJOIN invoice_items ii ON i.InvoiceId = ii.InvoiceId\nJOIN tracks t ON ii.TrackId = t.TrackId\nGROUP BY c.CustomerId, c.FirstName, c.LastName\nHAVING GenreCount > 9\nORDER BY GenreCount DESC\nLIMIT 10;'}`
responded: To identify customers who purchased tracks from more than nine different genres and calculate the total amount spent by these customers, I need to join several tables and perform the necessary aggregations.
Here's the plan:
1. Join the `customers`, `invoices`, `invoice_items`, and `tracks` tables to get the necessary data.
2. Group by `CustomerId` and count the distinct `GenreId` for each customer.
3. Filter out customers who purchased from more than nine different genres.
4. Calculate the total amount spent by these customers.
5. Sort the results by the highest number of genres.
Let's write and check the query.
```sql
SELECT c.CustomerId, c.FirstName, c.LastName, COUNT(DISTINCT t.GenreId) AS GenreCount, SUM(i.Total) AS TotalSpent
FROM customers c
JOIN invoices i ON c.CustomerId = i.CustomerId
JOIN invoice_items ii ON i.InvoiceId = ii.InvoiceId
JOIN tracks t ON ii.TrackId = t.TrackId
GROUP BY c.CustomerId, c.FirstName, c.LastName
HAVING GenreCount > 9
ORDER BY GenreCount DESC
LIMIT 10;
```
Invoking: `sql_db_query` with `{'query': 'SELECT c.CustomerId, c.FirstName, c.LastName, COUNT(DISTINCT t.GenreId) AS GenreCount, SUM(i.Total) AS TotalSpent\nFROM customers c\nJOIN invoices i ON c.CustomerId = i.CustomerId\nJOIN invoice_items ii ON i.InvoiceId = ii.InvoiceId\nJOIN tracks t ON ii.TrackId = t.TrackId\nGROUP BY c.CustomerId, c.FirstName, c.LastName\nHAVING GenreCount > 9\nORDER BY GenreCount DESC\nLIMIT 10;'}`
[(57, 'Luis', 'Rojas', 12, 415.6200000000001), (45, 'Ladislav', 'Kovács', 11, 446.6200000000003), (3, 'François', 'Tremblay', 10, 338.62000000000006), (14, 'Mark', 'Philips', 10, 334.6200000000001), (17, 'Jack', 'Smith', 10, 352.62000000000035), (24, 'Frank', 'Ralston', 10, 378.6200000000001), (34, 'João', 'Fernandes', 10, 352.62000000000035), (37, 'Fynn', 'Zimmermann', 10, 388.6200000000001)]Here are the customers who purchased tracks from more than nine different genres, along with the total amount they spent, sorted by the highest number of genres:
1. **Luis Rojas** - Purchased from 12 genres, Total Spent: $415.62
2. **Ladislav Kovács** - Purchased from 11 genres, Total Spent: $446.62
3. **François Tremblay** - Purchased from 10 genres, Total Spent: $338.62
4. **Mark Philips** - Purchased from 10 genres, Total Spent: $334.62
5. **Jack Smith** - Purchased from 10 genres, Total Spent: $352.62
6. **Frank Ralston** - Purchased from 10 genres, Total Spent: $378.62
7. **João Fernandes** - Purchased from 10 genres, Total Spent: $352.62
8. **Fynn Zimmermann** - Purchased from 10 genres, Total Spent: $388.62
Ce cas est très intéressant, car la réponse n’est pas bonne.
Notez qu’il y a une subtilité, dans cette base de données les informations financières sont gérées dans deux tables différentes, invoices et invoice_items.
Invoice_items correspond à l’achat d’une piste. Si un client achète 2 pistes, nous aurons alors 2 lignes liées à invoices.
Pour illustrer cet exemple, prenons un cas concret de la base de données, la facture id 1 a deux lignes rattachées donc un client a acheté 2 pistes pour un prix unitaire de 0,99 €. Nous avons donc 1,98 € dans la colonne du total de la ligne invoices.
Lorsque nous réalisons une requête, si nous ne regroupons pas les résultats (GROUP BY), nous aurons alors les lignes invoices dupliquées autant de fois qu’il y a de ligne invoice_items rattachées. Utiliser alors la fonction SUM ne donnera pas le bon résultat, ce qui est notre problème actuellement.
Si j’exécute cette requête nous pouvons constater ce résultat
SELECT i.* FROM invoices i
LEFT JOIN invoice_items ii ON i.InvoiceId=ii.InvoiceId
WHERE i.InvoiceId=1
Faire un SUM sur Total n’est pas absolument pas la bonne solution.
Si nous reprenons le résultat de notre requête SQL nous pouvons constater que Luis Rojas a dépensé 415,62 €. Ce montant provient de cette fonction SUM(i.Total) AS TotalSpent
Le fait d’avoir écrit the total amount spent by, le LLM se base donc sur la colonne total.
Nous ne pouvons pas maîtriser parfaitement l’interprétation du LLM et c’est d’ailleurs tout son intérêt, nous avons donc trouvé une solution afin de corriger ce petit problème.
L’agent utilisé est “create_sql_agent » et il prend en paramètre un suffixe. Nous pouvons donc créer un prompt complémentaire qui ajoute des instructions spécifiques.
Nous pouvons ajouter le code suivant :
[...]
suffix = """
Here is some additionnal information about the database,
there are two tables that deal with the subject of financial amount.
The 'Invoices' table and the 'Invoice_items' table. You must always
rely on the 'quantity' and 'UnitPrice' columns in order to make
calculations relating to a financial aspect. You should NEVER
use the 'Total' column of the 'Invoices' table. Use this information
only when necessary.
"""
agent_executor = create_sql_agent(model, db=db, agent_type="openai-tools", verbose=True, suffix=suffix)
[...]
Nous précisons au LLM la subtilité de cette base en ce qui concerne l’aspect financier de la demande. A présent, dès lors que nous demanderons au LLM une information financière, il utilisera cette fonction SUM(ii.UnitPrice * ii.Quantity)
Après avoir relancé le même prompt avec ce changement, voici notre résultat, qui lui est correct !
1. **Luis Rojas** - Purchased from 12 genres, Total Amount Spent: $46.62
2. **Ladislav Kovács** - Purchased from 11 genres, Total Amount Spent: $45.62
3. **François Tremblay** - Purchased from 10 genres, Total Amount Spent: $39.62
4. **Mark Philips** - Purchased from 10 genres, Total Amount Spent: $37.62
5. **Jack Smith** - Purchased from 10 genres, Total Amount Spent: $39.62
6. **Frank Ralston** - Purchased from 10 genres, Total Amount Spent: $43.62
7. **João Fernandes** - Purchased from 10 genres, Total Amount Spent: $39.62
8. **Fynn Zimmermann** - Purchased from 10 genres, Total Amount Spent: $43.62
Conclusion
Les résultats sont plutôt bons, les requêtes sont construites de manière cohérente. Cependant, il faut prendre en compte le nom des tables ainsi que des colonnes de la base de données.
En effet, le modèle de langage interprète les demandes et recherche des cohérences dans le nom des tables et des colonnes. Si les tables sont mal nommées, cela ne fonctionnera pas.
Modifier ces éléments dans une base de données existante peut se révéler assez complexe. Comme vu précédemment, il est donc possible d’ajouter du contexte au LLM afin de créer une logique entre les tables et les colonnes.
Il devient donc très intéressant de travailler par itération sur une base de données existante et les résultats pourront être satisfaisants.
Merci d’avoir suivi cet article, afin de tester par vos propres moyens, vous trouverez le lien ci-dessous afin de tester par vous même.
Puisque que les entreprises doivent gérer des données de plus en plus complexes et qu’il devient nécessaire d’y accéder de manière rapide et simple, on a conduit plusieurs tests pour voir s’il était possible de laisser les utilisateurs faire des requêtes en langage naturel. On s’est dit que cela pouvait faire un super article !
Donc, dans cet article, nous montrons comment l’intégration de l’API d’OpenAI permet vraiment d’ouvrir l’accès aux données aux utilisateurs non-experts.
Note : Nous utilisons le modèle GPT4 de OpenAI mais d’autres modèles capables de générer du code sont disponibles tel que Mistral.
1. La data encore la data
L’accès à des données précises et pertinentes permet de prendre des décisions ou d’optimiser des processus. Pourtant, l’accès et l’interrogation des bases de données restent souvent complexes. Les requêtes SQL peuvent être difficiles à maîtriser parce qu’elles nécessitent des compétences techniques.
Les utilisateurs finaux, souvent non familiers avec les langages de requête et les structures de bases de données, peuvent peiner à interpréter les résultats. Alors, pour surmonter ces défis, les entreprises investissent dans des solutions de BI qui simplifient l’accès aux données et automatisent l’analyse.
Les outils de visualisation de données permettent aux décideurs de tous niveaux de comprendre et d’exploiter les informations sans nécessiter une expertise technique approfondie. Mais il y a encore des limites, par exemple, on ne peut évidemment manipuler que les données qui sont intégrées et y connecter de nouveaux outils n’est pas forcément simple. La personnalisation des requêtes peut être complexe (sans parler du coût de ces outils).
Bref, on peut encore faire des progrès ! Et, une bonne piste est l’IA…
2. L’API d’OpenAI pourrait bien être une révolution dans l’accès aux données
L’API d’OpenAI représente une avancée majeure dans le domaine du traitement du langage naturel (NLP), offrant des capacités impressionnantes pour comprendre et générer du texte en langage humain. Cette API permet aux utilisateurs de poser des questions et de recevoir des réponses dans un langage clair et naturel, rendant les interactions avec les systèmes beaucoup plus simples.
L’API peut même transformer la manière dont les utilisateurs interagissent avec les bases de données en permettant de convertir des questions en langage naturel en instructions SQL.
Prenons un exemple complexe : un utilisateur pourrait vouloir obtenir des informations sur les tendances de vente et de retour de produits dans une entreprise. En langage naturel, l’utilisateur pourrait demander : « Quels sont les cinq produits les plus vendus et les plus retournés au cours des six derniers mois, et quelle est la différence moyenne de revenus entre les ventes et les retours pour ces produits ? ». Si, on lui a préalablement donné le modèle de données, l’API ChatGPT est capable de traduire cette demande en une série de requêtes SQL :
WITH TopProducts AS (
SELECT product_id,
SUM(quantity_sold) AS total_sales,
SUM(quantity_returned) AS total_returns
FROM sales
WHERE sale_date >= DATE_SUB(CURDATE(), INTERVAL 6 MONTH)
GROUP BY product_id
ORDER BY total_sales DESC
LIMIT 5
)
SELECT p.product_name, tp.total_sales, tp.total_returns,
(tp.total_sales * p.sale_price - tp.total_returns * p.return_price) / 6 AS average_revenue_difference
FROM TopProducts tp
JOIN products p ON tp.product_id = p.product_id;
Bon, c’est pas mal mais comment l’intégrer dans mon application ?
3. “Call Me”
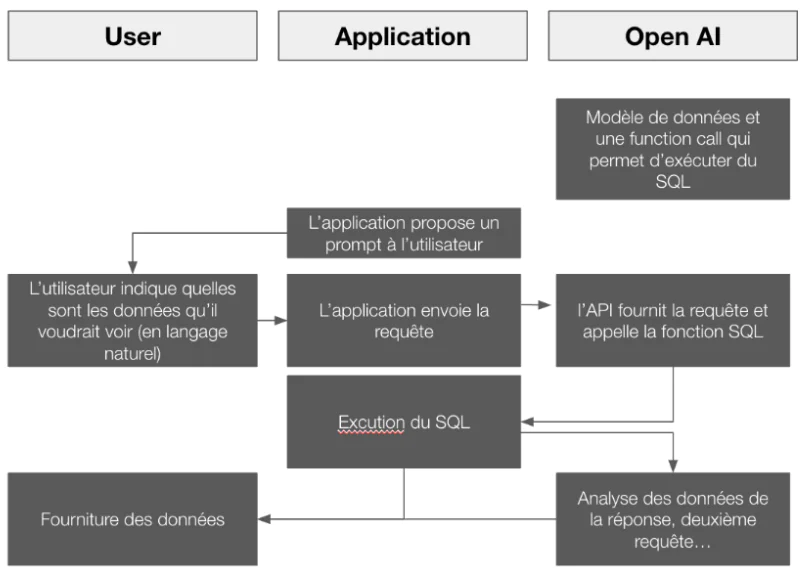
Non, ce n’est pas pour parler de Blondie (oui, j’ai des réfs de vieux) mais OpenAi vient de développer un mode “function calling” particulièrement intéressant.
Le « function calling » permet au LLM (Large Language Model) modèle d’identifier quand une tâche requiert une exécution de fonction et d’appeler directement une fonction définie dans l’application de l’utilisateur. Cette fonctionnalité permet de donner la possibilité au modèle d’exécuter des actions que nous allons définir comme envoyer un e-mail, d’interroger des bases de données, de récupérer des informations, et bien plus encore…
Donc, on peut développer une solution qui marcherait selon le principe suivant :
Pas mal non ? L’avantage est que l’on donne pas ses données à OpenAi.
4. Enjeux de sécurité
Il y a deux risques avec ce type de développement. Le premier est que si quelqu’un réussit à tromper OpenAi, il pourrait faire une requête INSERT ou DELETE (voire DROP) au lieu d’une requête SELECT. L’autre serait de réussir à sortir de son « domaine » (la liste des données que l’on a le droit de lire).
Donc, l’approche est bonne si l’on est administrateur et qu’on a le droit de tout voir, mais si l’on n’a le droit de voir qu’une partie des données, il est très difficile de garantir que la requête générée ne retournera pas des données confidentielles.
Dans ces conditions, il faudrait mettre en place un parseur de requêtes qui ajoute des filtres à la volée. Cela n’est pas trivial, mais c’est possible.
D’autres modèles que OpenAi peuvent aussi répondre au problème de sécurité des données. Des modèles comme Mistral peuvent tourner en local et sont plutôt bons pour la génération de code.
Une autre solution (proposée par nos équipes à Lyon) serait d’avoir une base de données répliquée et étanche. Dans ce cas là, plus de problème pour la manipulation des données (mais il reste quand même le second risque sur la confidentialité de certaines données).
Bref, à défaut d’avoir une connexion directe avec la BDD, l’API d’OpenAi peut quand même aider pour rédiger/corriger une requête SQL ce qui peut déjà faire gagner beaucoup de temps !
Conclusion
On ne va pas se mentir, la question de laisser l’IA accéder aux données peut vous rendre frileux, on le comprend. Mais on pense quand même que c’est une opportunité sans précédent pour transformer la manière dont les entreprises interagissent avec leurs données. En simplifiant l’accès aux données et en rendant les requêtes plus intuitives, cette manière d’exploiter l’IA est un vrai use case de l’IA (pour une fois ?).
Le Bank Tech Day 2024 est un événement incontournable pour les acteurs du secteur bancaire, réunissant experts, décideurs et innovateurs autour des défis et des opportunités technologiques qui façonnent l’avenir de la finance. Si vous l’avez manqué, voici les principaux enseignements et enjeux technologiques que nous avons retenus : IA !
L’intelligence artificielle en passe de révolutionner l’expérience client
L’intelligence artificielle (IA) a été au cœur des discussions, notamment pour améliorer l’expérience client. Les banques et les institutions financières investissent en priorité dans l’optimisation des processus KYC (Know Your Customer) et KYB (Know Your Business), ce qui non seulement permet de prévenir les fraudes potentielles mais aussi de se conformer aux lois et réglementations nationales et internationales.
C’est dans ce contexte que des solutions IA sont de plus en plus utilisées pour créer des scénarios prédictifs, et assurer une maintenance continue des données KYC et KYB dans le but de mettre en place des dispositifs pour améliorer la satisfaction client
Cependant une grande importance doit être donnée à la qualité des données pour entraîner les différents modèles d’IA afin d’obtenir des résultats pertinents et proposer des services satisfaisants.
Dans une ère où le client peut changer rapidement de banque, intégrer des outils IA permet aussi d’augmenter le conseiller bancaire. Ce n’est pas le futur mais on y est presque :
Traitement et analyse des demandes des clients au téléphone
Au téléphone, une analyse des échanges permettrait de suggérer plus rapidement des solutions en les proposant aux conseillers bancaires.
Par exemple : suite à la discussion, l’IA propose de noter un RDV dans l’agenda du conseiller bancaire du client, ou il suggère d’envoyer un email au client avec des solutions de financement…
A la clé : une plus grande efficacité du conseiller, une réduction des temps de formation…
Utilisation de chatbot reposant sur l’IA dans l’espace client
L’IA peut désormais traiter des demandes d’informations très variées tout en proposant une expérience utilisateur d’une grande qualité. Ainsi, le client pourra en une seule question demander une analyse de ses dépenses, poser des questions de facturation où accéder aux informations des produits. Il faut néanmoins rester vigilant sur la fiabilité de l’information et le respect des normes réglementaires. Le chatbot vient ainsi en complément des échanges téléphoniques afin de répondre à une partie des demandes et gagner en efficacité opérationnelle.
Proposer une transcription automatique des réunions
Pour continuer dans la même veine, lors des réunions client, il est possible d’effectuer une retranscription automatique des échanges afin de les synthétiser dans le CRM. Il serait même possible de simplifier les saisies avec les échanges (montant du financement par exemple) voire d’analyser les sentiments des clients pour avoir des indicateurs sur la qualité du service (“big brother is watching you”).
Bank Tech Day 2024 – La DSP3 arrive !
La DSP3, ou Directive sur les services de paiement 3, est un ensemble de nouvelles règles européennes qui visent à rendre les paiements plus sûrs, plus innovants et plus centrés sur le client.
Quels sont les objectifs de la DSP3 ?
Sécurité renforcée pour mieux protéger les consommateurs contre la fraude
APIs Open banking boosté : L’expérimentation, l’exploitation et l’optimisation des APIs d’Open Bankin pour atteindre la maturité technologique permettant leur ouverture et accessibilité mais aussi leur sécurité.
Lutte contre la fraude optimisée : les acteurs peuvent partager des infos sur les transactions frauduleuses pour mieux les identifier et les bloquer.
Protection des consommateurs accrue : plus de contrôle sur leurs données et plus de transparence dans les services de paiement.
Comment s’adapter ? ️
Suite au Bank Tech Day 2024, les acteurs du secteur devront s’appuyer sur des solutions technologiques innovantes telles que l’authentification forte, les plateformes d’open banking sécurisées, les systèmes de détection de fraude basés sur l’IA, et puis surtout des outils de gestion des données robustes. ️
Banking As a Service : les API au coeurs des partenariats entre banque et Fintech
L’ère des APIs permet le développement de nouveaux business models, tels que la Banking-as-a-Service (BaaS) ou Open Banking. Ces modèles favorisent la co-création de valeur avec des partenaires, offrant de nouveaux services aux clients.
Les APIs facilitent la collaboration entre les grandes banques et les fintechs, permettant une intégration rapide et efficace des nouvelles technologies ou offres. Les API sont aussi la clé de l’utilisation de l’IA à partir des données clients pour proposer des solutions plus pertinentes et adaptées. Évidemment, la mise en œuvre de ces APIs doit respecter les réglementations en vigueur pour garantir la sécurité et la confidentialité des données clients.
Ce sujet, nous le connaissons bien chez TheCodingMachine. Nous avons eu l’opportunité de mettre en place techniquement de telles solutions notamment en intégrant des solutions comme Bridge ou Ubble au sein des parcours utilisateurs de nos clients.
Quelle banque pour demain ?
Le client est au cœur de la stratégie : l’avenir du secteur se jouera avec les banques qui développent un fort relationnel avec leur client, qui misent sur un accompagnement proactif. Il faut être facilement joignable et offrir un accompagnement à la fois expert et personnalisé à tout moment. Il est estimé que 30% des ventes passeront en 2025 par des leviers digitaux.
Alors, comment faire ? Il faut prioriser la satisfaction client au niveau des innovations et garantir le plus possible une expérience fluide, sécurisée et personnalisée.
L’avenir de la banque appartiendra certainement à ceux qui sauront placer l’expertise et la confiance au cœur de leur relation client notamment en exploitant à bon escient leurs données à travers les API.
À retenir du Bank Tech Day 2024
Le Bank Tech Day 2024 a mis en lumière les nombreux défis et opportunités technologiques auxquels le secteur bancaire doit faire face : L’IA, la DSP3, la prévention contre la fraude, les business models digitaux, la collaboration avec les fintechs et la confiance client sont les clés pour construire la banque de demain.
Évidemment, si vous souhaitez parler de projets IA, API, relation client et même DSP3, on se tient à votre disposition !